sglang中的mlp
sglang中的mlp
gogongxtmlp计算流程
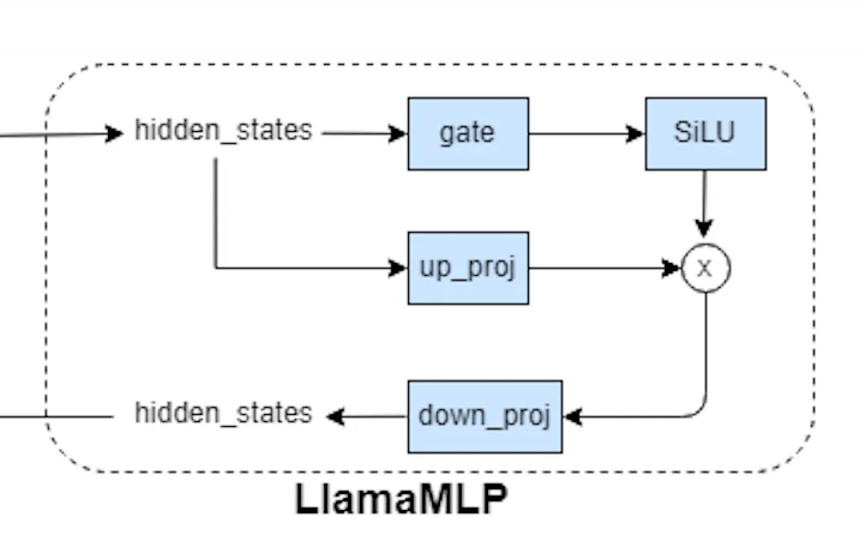
先来看一下上图经典mlp的计算:
gate和up的proj,可以cat起来一起算
gate后有一个silu激活,激活后的值和up后的进行点乘,这两个操作也是一起做的
点乘结果给到down_proj就是最后的输出
对于非moe的mlp计算,qwen2和qwen3都一样的用的类Qwen2MLP
核心计算MergedColumnParallelLinear和RowParallelLinear就是使用torch.linear的计算,如果是tp,就是直接进行矩阵分块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class Qwen2MLP(nn.Module):
def __init__(
self,
hidden_size: int,
intermediate_size: int,
hidden_act: str,
quant_config: Optional[QuantizationConfig] = None,
prefix: str = "",
) -> None:
super().__init__()
self.gate_up_proj = MergedColumnParallelLinear(
hidden_size,
[intermediate_size] * 2,
bias=False,
quant_config=quant_config,
prefix=add_prefix("gate_up_proj", prefix),
)
self.down_proj = RowParallelLinear(
intermediate_size,
hidden_size,
bias=False,
quant_config=quant_config,
prefix=add_prefix("down_proj", prefix),
)
if hidden_act != "silu":
raise ValueError(
f"Unsupported activation: {hidden_act}. "
"Only silu is supported for now."
)
def SiluAndMul(x: torch.Tensor) -> torch.Tensor:
d = x.shape[-1] // 2
return F.silu(x[..., :d]) * x[..., d:]
self.act_fn = SiluAndMul()
def forward(self, x):
if get_global_server_args().rl_on_policy_target is not None:
x = x.bfloat16()
gate_up, _ = self.gate_up_proj(x)
x = self.act_fn(gate_up)
x, _ = self.down_proj(x)
return x上面的计算都不是很复杂,也不太有优化空间,我们着重关注下面moe的mlp计算
MoE 计算流程总结
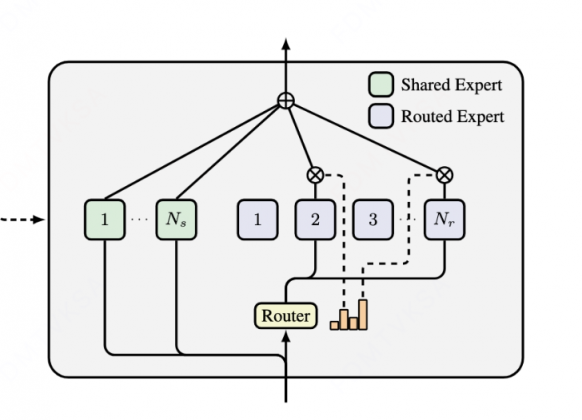
下图是带shared_experts和router_experts的moe
- 在tp情况下,两种专家都是在所有卡上做切分,唯一不同就是路由专家会有一个gate的概率和topk筛选进行选择计算
- 在ep情况下,共享专家是每张卡上都有,路由专家是由所有卡之间进行调度(deepep)后面单开deepep详细讲
下面以qwen3-next的moe来看,其实和qwen3-moe啥的都是差不多的
调用链路:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Qwen3NextModel.forward()
↓
Qwen3HybridLinearDecoderLayer.forward() # softmax attention也是一样的
↓
self.mlp(hidden_states) # Qwen2MoeSparseMoeBlock
↓
Qwen2MoeSparseMoeBlock.forward()
↓
_forward_shared_experts() + _forward_router_experts() # _forward_shared_experts计算共享专家,_forward_router_experts计算moe路由专家
↓
self.experts(hidden_states, topk_output) # FusedMoE
↓
FusedMoE.forward()
↓
self.run_moe_core(dispatch_output)
↓
self.quant_method.apply(layer=self, dispatch_output=dispatch_output)
↓
UnquantizedFusedMoEMethod.apply() → MoE Kernels (Triton/FlashInfer)下面是具体的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
self.mlp = Qwen2MoeSparseMoeBlock(
layer_id=layer_id,
config=config,
quant_config=quant_config,
alt_stream=alt_stream,
prefix=add_prefix("mlp", prefix),
)
class Qwen2MoeSparseMoeBlock(nn.Module):
def __init__(
self,
layer_id: int,
config: PretrainedConfig,
quant_config: Optional[QuantizationConfig] = None,
alt_stream: Optional[torch.cuda.Stream] = None,
prefix: str = "",
):
super().__init__()
self.tp_size = get_tensor_model_parallel_world_size()
self.layer_id = layer_id
self.alt_stream = alt_stream
if self.tp_size > config.num_experts:
raise ValueError(
f"Tensor parallel size {self.tp_size} is greater than "
f"the number of experts {config.num_experts}."
)
self.topk = TopK(
top_k=config.num_experts_per_tok,
renormalize=config.norm_topk_prob,
)
self.experts = get_moe_impl_class(quant_config)(
layer_id=self.layer_id,
top_k=config.num_experts_per_tok,
num_experts=config.num_experts
+ get_global_server_args().ep_num_redundant_experts,
hidden_size=config.hidden_size,
intermediate_size=config.moe_intermediate_size,
quant_config=quant_config,
prefix=add_prefix("experts", prefix),
routing_method_type=RoutingMethodType.RenormalizeNaive,
)
self.gate = ReplicatedLinear(
config.hidden_size,
config.num_experts,
bias=False,
quant_config=None,
prefix=add_prefix("gate", prefix),
)
if config.shared_expert_intermediate_size > 0:
self.shared_expert = Qwen2MoeMLP(
hidden_size=config.hidden_size,
intermediate_size=config.shared_expert_intermediate_size,
hidden_act=config.hidden_act,
quant_config=quant_config,
reduce_results=False,
prefix=add_prefix("shared_expert", prefix),
**(
dict(tp_rank=0, tp_size=1)
if get_moe_a2a_backend().is_deepep()
else {}
),
)
else:
self.shared_expert = None
self.shared_expert_gate = torch.nn.Linear(config.hidden_size, 1, bias=False)
if get_moe_a2a_backend().is_deepep():
# TODO: we will support tp < ep in the future
self.ep_size = get_moe_expert_parallel_world_size()
self.num_experts = (
config.num_experts + get_global_server_args().ep_num_redundant_experts
)
self.top_k = config.num_experts_per_tok
def get_moe_weights(self):
return [
x.data
for name, x in self.experts.named_parameters()
if name not in ["correction_bias"]
]
def _forward_shared_experts(self, hidden_states: torch.Tensor):
shared_output = None
if self.shared_expert is not None:
shared_output = self.shared_expert(hidden_states)
if self.shared_expert_gate is not None:
shared_output = (
F.sigmoid(self.shared_expert_gate(hidden_states)) * shared_output
)
return shared_output
def _forward_deepep(self, hidden_states: torch.Tensor, forward_batch: ForwardBatch):
shared_output = None
if hidden_states.shape[0] > 0:
# router_logits: (num_tokens, n_experts)
router_logits, _ = self.gate(hidden_states)
shared_output = self._forward_shared_experts(hidden_states)
topk_output = self.topk(
hidden_states,
router_logits,
num_token_non_padded=forward_batch.num_token_non_padded,
expert_location_dispatch_info=ExpertLocationDispatchInfo.init_new(
layer_id=self.layer_id,
),
)
else:
topk_output = self.topk.empty_topk_output(hidden_states.device)
final_hidden_states = self.experts(
hidden_states=hidden_states,
topk_output=topk_output,
)
if shared_output is not None:
final_hidden_states.add_(shared_output)
return final_hidden_states
def _forward_router_experts(self, hidden_states: torch.Tensor):
# router_logits: (num_tokens, n_experts)
router_logits, _ = self.gate(hidden_states)
topk_output = self.topk(hidden_states, router_logits)
return self.experts(hidden_states, topk_output)
def forward_normal_dual_stream(
self,
hidden_states: torch.Tensor,
) -> torch.Tensor:
current_stream = torch.cuda.current_stream()
self.alt_stream.wait_stream(current_stream)
shared_output = self._forward_shared_experts(hidden_states.clone())
with torch.cuda.stream(self.alt_stream):
router_output = self._forward_router_experts(hidden_states)
current_stream.wait_stream(self.alt_stream)
return router_output, shared_output
def forward(
self,
hidden_states: torch.Tensor,
forward_batch: Optional[ForwardBatch] = None,
use_reduce_scatter: bool = False,
) -> torch.Tensor:
num_tokens, hidden_dim = hidden_states.shape
hidden_states = hidden_states.view(-1, hidden_dim)
# 这里可以选择使用deepep进行moe推理
if get_moe_a2a_backend().is_deepep():
return self._forward_deepep(hidden_states, forward_batch)
# 当输入序列比较短,使用cuda stream,并且是decode时候,因为这个时候计算量不大
# 使用两个流可以并行计算shared和router的experts,尽量跑满计算
DUAL_STREAM_TOKEN_THRESHOLD = 1024
if (
self.alt_stream is not None
and hidden_states.shape[0] > 0
and hidden_states.shape[0] <= DUAL_STREAM_TOKEN_THRESHOLD
and get_is_capture_mode()
):
final_hidden_states, shared_output = self.forward_normal_dual_stream(
hidden_states
)
else:
# 其余情况就是串行推理(因为每个都有一定计算量,可以跑满)
shared_output = self._forward_shared_experts(hidden_states)
final_hidden_states = self._forward_router_experts(hidden_states)
if shared_output is not None:
final_hidden_states = final_hidden_states + shared_output
if self.tp_size > 1 and not use_reduce_scatter:
final_hidden_states = tensor_model_parallel_all_reduce(final_hidden_states)
return final_hidden_states.view(num_tokens, hidden_dim)关注代码:
- 还支持
deepep做moe分发,后面说到deepseek的时候再说deepep - 着重关注两个推理:
_forward_shared_experts和_forward_router_experts_forward_shared_experts:计算共享专家,也就是很普通的linear,Qwen2MoeMLP和之前讲过的普通mlp差不多_forward_router_experts:计算路由专家,通过gate和topk知道选择的专家,然后通过self.experts进行核心计算,因为整体很稀疏,这里的计算使用了triton的算子,最后是FusedMoE的UnquantizedFusedMoEMethod进行计算



喜欢这篇文章的人也看了

png)

评论
匿名评论隐私政策






