qwen3-next结构和推理代码
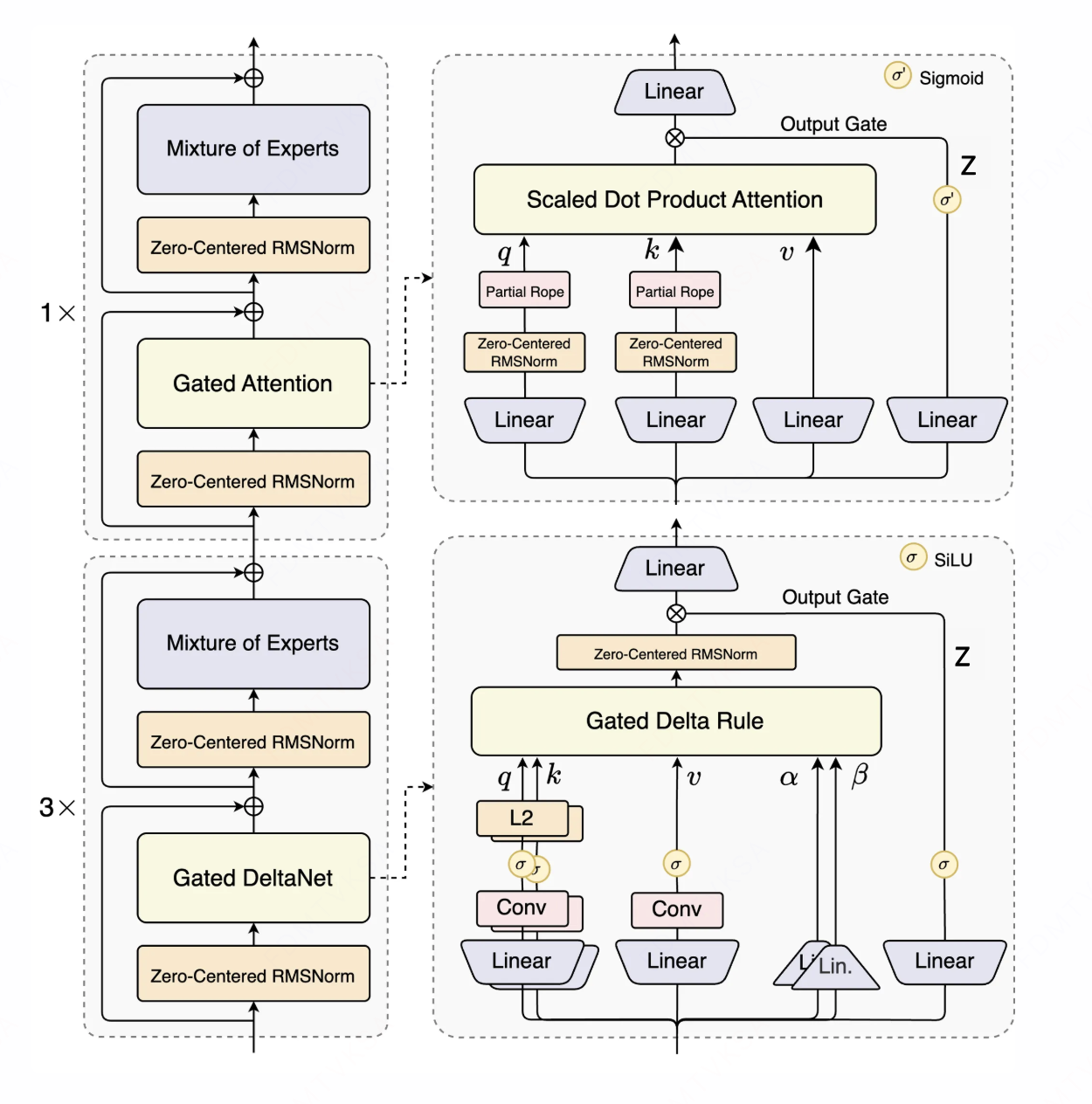
qwen3-next结构和推理代码
gogongxt有一个讲的很好:https://zhuanlan.zhihu.com/p/1971883340031328850
qwen3-next结构
模型共计 48 层,被划分为 12 组(每组 4 层)。
- 前 3 层 采用 Gated DeltaNet Linear Attention,能够显著提升计算效率并降低显存占用。
- 第 4 层 为传统的 Full Self Softmax Attention,在输出阶段额外加入了一道门控。
Gated DeltaNet 分析
关于Gated DeltaNet计算可以看这张图详细一点:
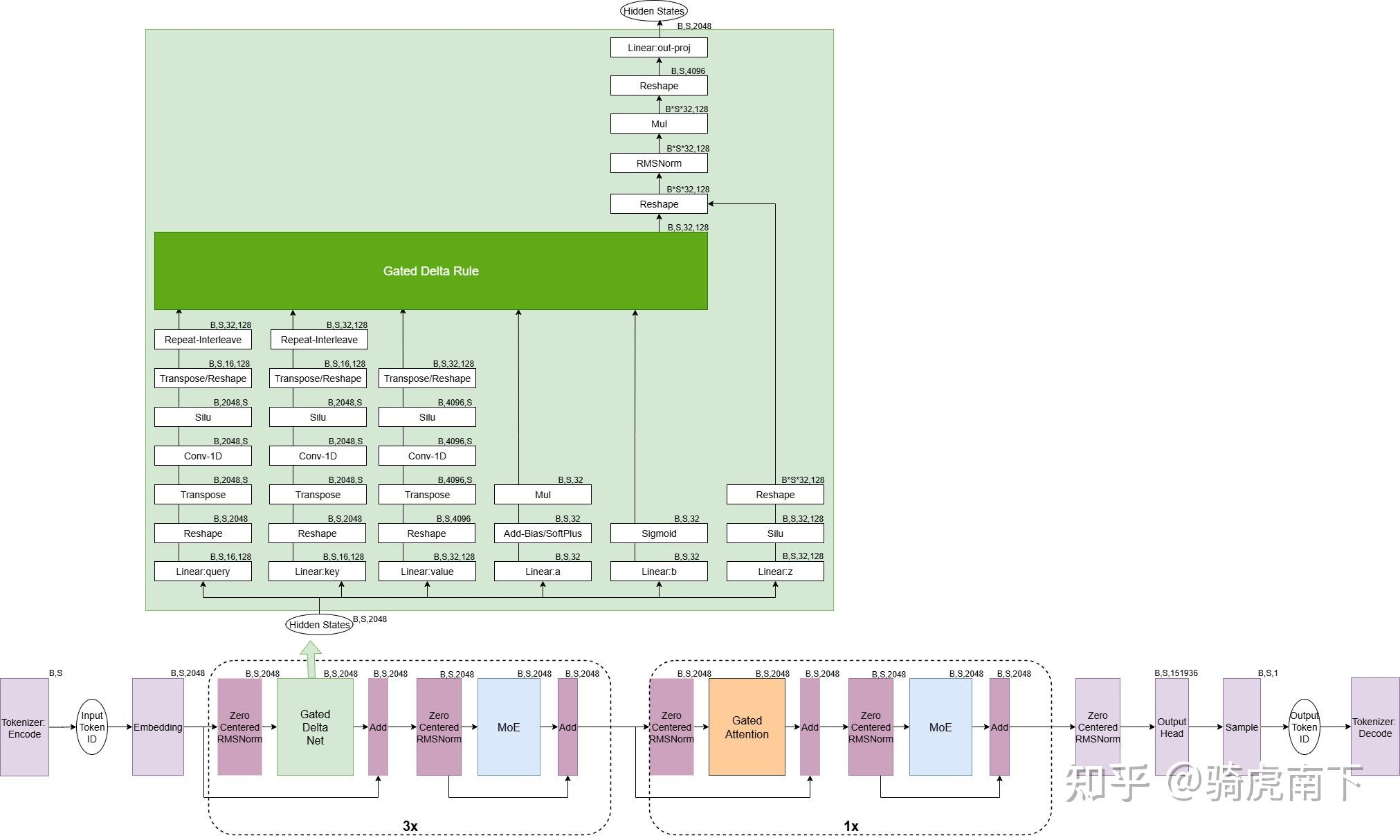
计算顺序:
- 五个linear矩阵乘
计算一维卷积 计算SiLU激活函数 计算 Gated Delta RuleGated Delta Rule输入进行Zero-Centered RMSNromRMSNorm输出和的结果进行点乘
下面的代码主要来自transformers库,做了部分删减
1. 计算linear矩阵乘
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
self.config = config
self.hidden_size = config.hidden_size # 隐藏层维度
self.num_v_heads = config.linear_num_value_heads # v的头数
self.num_k_heads = config.linear_num_key_heads # k的头数
self.head_k_dim = config.linear_key_head_dim # 单头k的维度
self.head_v_dim = config.linear_value_head_dim # 单头v的维度
self.key_dim = self.head_k_dim * self.num_k_heads # 总的k的维度
self.value_dim = self.head_v_dim * self.num_v_heads # 总的v的维度
projection_size_qkvz = self.key_dim * 2 + self.value_dim * 2 # qkvz投影
projection_size_ba = self.num_v_heads * 2 # ba投影
self.in_proj_qkvz = nn.Linear(self.hidden_size, projection_size_qkvz, bias=False)
self.in_proj_ba = nn.Linear(self.hidden_size, projection_size_ba, bias=False)
# [b, s, key_dim * 2 + value_dim * 2]
projected_states_qkvz = self.in_proj_qkvz(hidden_states)
# [b, s, num_v_heads * 2]
projected_states_ba = self.in_proj_ba(hidden_states)
# query, key:[b, s, key_dim]
# value, z:[b, s, value_dim]
query, key, value, z = torch.split(
projected_states_qkvz,
[self.key_dim, self.key_dim, self.value_dim, self.value_dim],
dim=-1)
# b,a:[b, s, num_v_heads]
b, a = torch.split(
projected_states_ba,
[self.num_v_heads, self.num_v_heads],
dim=-1)2. 在最后一个维度拼接QKV,做conv1d,做完卷积后做silu激活函数
1
2
3
4
5
6
7
8
# 拼接qkv
mixed_qkv = torch.cat((query, key, value), dim=-1) # [b,s,key_dim*2 + value_dim]
# 方便做卷积,把sequence放到最后面
mixed_qkv = mixed_qkv.transpose(1, 2) # [b, key_di=*2 + value_dim, s]
# 卷积实现+silu激活
mixed_qkv = F.silu(self.conv1d(mixed_qkv)[:, :, :seq_len])
# conv之后再交换回来
mixed_qkv = mixed_qkv.transpose(1, 2) # [b, s, key_dim*2 + value_dim]注意这里做卷积分为prefill和decode,prefill阶段可以并行做,decode是增量的,推理时只需要存储步长大小的特征向量,这样decode就只需要做增量部分。
存储计算的结果,为后面decode做缓存:
1
2
3
conv_state = F.pad(mixed_qkv, (self.conv_kernel_size - mixed_qkv.shape[-1], 0))
cache_params.conv_states[self.layer_idx] = conv_state
mixed_qkv = F.silu(self.conv1d(mixed_qkv)[:, :, :s])3. 在最后一个维度做split,分别得到QKV
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
query, key, value = torch.split(
mixed_qkv,
[
self.key_dim,
self.key_dim,
self.value_dim,
],
dim=-1,
)
query = query.reshape(bs, s, -1, self.head_k_dim) # [b,s,num_k_heads, head_k_dim]
key = key.reshape(bs, s, -1, self.head_k_dim) # [b,s,num_k_heads, head_k_dim]
value = value.reshape(bs, s, -1, self.head_v_dim) # [b,s,num_v_heads, head_v_dim]
# 类似于GQA,保证head数一致,此时num_v_heads=num_k_heads
if self.num_v_heads // self.num_k_heads > 1:
query = query.repeat_interleave(self.num_v_heads // self.num_k_heads, dim=2)
key = key.repeat_interleave(self.num_v_heads // self.num_k_heads, dim=2)这样操作完之后num_v_heads=num_k_heads,后面统一用num_heads表示这两个值
4. 处理
1
2
3
4
5
6
7
8
# 处理alpha 得到遗忘门$g$
self.dt_bias = nn.Parameter(torch.ones(self.num_v_heads)) # [num_heads]
A = torch.empty(self.num_v_heads).uniform_(0, 16) # [num_heads]
self.A_log = nn.Parameter(torch.log(A)) # [num_heads]
g = -self.A_log.float().exp() * F.softplus(a.float() + self.dt_bias) # [b, s, num_heads]
# 处理beta
beta = b.sigmoid()至此我们的gated delta的输入参数都准备好了,有
5. 计算Gated Delta Rule
关注推理计算公式:
下面的函数是prefill的计算
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
def torch_recurrent_gated_delta_rule(
query, key, value, g, beta, initial_state, output_final_state, use_qk_l2norm_in_kernel=False
):
initial_dtype = query.dtype
# 对qk做l2norm标准化
if use_qk_l2norm_in_kernel:
query = l2norm(query, dim=-1, eps=1e-6)
key = l2norm(key, dim=-1, eps=1e-6)
query, key, value, beta, g = [
x.transpose(1, 2).contiguous().to(torch.float32) for x in (query, key, value, beta, g)
]
batch_size, num_heads, sequence_length, k_head_dim = key.shape
v_head_dim = value.shape[-1]
scale = 1 / (query.shape[-1] ** 0.5)
query = query * scale
# 创建完整的注意力输出矩阵
core_attn_out = torch.zeros(batch_size, num_heads, sequence_length, v_head_dim).to(value)
# 记录上一时刻的注意力输出矩阵
last_recurrent_state = (
torch.zeros(batch_size, num_heads, k_head_dim, v_head_dim).to(value)
if initial_state is None
else initial_state.to(value)
)
# 遍历整个序列长度
for i in range(sequence_length):
# 取出当前t时刻的qkvgb
q_t = query[:, :, i]
k_t = key[:, :, i]
v_t = value[:, :, i]
g_t = g[:, :, i].exp().unsqueeze(-1).unsqueeze(-1)
beta_t = beta[:, :, i].unsqueeze(-1)
# 对应到下面的门控的注意力计算公式
last_recurrent_state = last_recurrent_state * g_t # 计算aS_{t-1}
kv_mem = (last_recurrent_state * k_t.unsqueeze(-1)).sum(dim=-2) # 计算aS_{t-1}k
delta = (v_t - kv_mem) * beta_t # 计算 (v-aS_{t-1}k)b
last_recurrent_state = last_recurrent_state + k_t.unsqueeze(-1) * delta.unsqueeze(-2) # 计算完整的
core_attn_out[:, :, i] = (last_recurrent_state * q_t.unsqueeze(-1)).sum(dim=-2)
if not output_final_state:
last_recurrent_state = None
# [b,s,num_heads,head_v_dim]
core_attn_out = core_attn_out.transpose(1, 2).contiguous().to(initial_dtype)
return core_attn_out, last_recurrent_state由此可以看出,Delta Gated就像RNN一样没法并行计算,需要一个token一个token做计算,在prefill时效率也很低
可以考虑把序列切成chunk,chunk间并行计算,计算后再计算每个chunk,提高计算并行性
6. 计算完成后对门控z做silu和结果归一化
1
2
3
4
5
6
7
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
# Norm before gate
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
hidden_states = self.weight * hidden_states.to(input_dtype)
hidden_states = hidden_states * F.silu(gate.to(torch.float32))7. 最后再做o投影得到最终结果
1
output = self.out_proj(core_attn_out)Zero-Centered RMSNrom分析
其实这个没啥特别的就只是在普通的RMSNorm的权重上加上了1,并在训练时初始化为0
普通的rmsnorm:
优化zero-centered的rmsnorm:
下面是Zero-Centered RMSNorm代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def forward_native(
self,
x: torch.Tensor,
residual: Optional[torch.Tensor] = None,
) -> Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]:
orig_dtype = x.dtype
if residual is not None:
x = x + residual
residual = x
x = x.float()
variance = x.pow(2).mean(dim=-1, keepdim=True)
x = x * torch.rsqrt(variance + self.variance_epsilon)
x = x * (1.0 + self.weight.float()) # 唯一区别,这里weight加上了1
x = x.to(orig_dtype)
return x if residual is None else (x, residual)qwen3-next-80B-A3B config.json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
{
"architectures": [
"Qwen3NextForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 151643,
"decoder_sparse_step": 1,
"eos_token_id": 151645,
"full_attention_interval": 4,
"head_dim": 256,
"hidden_act": "silu",
"hidden_size": 2048,
"initializer_range": 0.02,
"intermediate_size": 5120,
"linear_conv_kernel_dim": 4,
"linear_key_head_dim": 128,
"linear_num_key_heads": 16,
"linear_num_value_heads": 32,
"linear_value_head_dim": 128,
"max_position_embeddings": 262144,
"mlp_only_layers": [],
"model_type": "qwen3_next",
"moe_intermediate_size": 512,
"norm_topk_prob": true,
"num_attention_heads": 16,
"num_experts": 512,
"num_experts_per_tok": 10,
"num_hidden_layers": 48,
"num_key_value_heads": 2,
"output_router_logits": false,
"partial_rotary_factor": 0.25,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 10000000,
"router_aux_loss_coef": 0.001,
"shared_expert_intermediate_size": 512,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.57.0.dev0",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 151936
}GDN对比softmax attention什么时候节约kvcache
GDN 的存储量由 SSM 状态(State)和 Conv
状态(Buffer)两部分组成,其大小不随序列长度
A. SSM 部分
SSM 状态本质上是一个维度为
B. Conv 部分
Conv 状态需要缓存
对于 GQA(softmax attention)cache(与 seq_len 线性相关),存储量为:
对于qwen3-next架构:
1
2
3
4
5
6
7
8
9
10
GDN:
"linear_num_key_heads": 16,
"linear_num_value_heads": 32,
"linear_value_head_dim": 128,
"linear_key_head_dim": 128,
"linear_conv_kernel_dim": 4,
GQA:
"num_key_value_heads": 2,
"head_dim": 256,可以计算得到seqlen为536
计算 GDN 总 Cache:
- SSM:
- Conv:
- GDN Total:
计算 GQA 总 Cache:
计算临界点 (Break-even Point):











