8-多模态模型加载和适配

8-多模态模型加载和适配
gogongxt支持新模型:
多模态大语言模型推理原理与实现
基于 nano-sglang 框架的多模态模型处理机制
多模态模型概述
多模态模型的核心思想是将不同模态的数据映射到统一的语义空间,然后利用语言模型进行理解和生成:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
┌─────────────┐ ┌─────────────┐ ┌──────────────┐
│ 文本输入 │ ──→ │ Tokenizer │ ──→ │ Token Embed │
├─────────────┤ ├─────────────┤ ├──────────────┤
│ 图像输入 │ ──→ │ Vision Enc │ ──→ │ Vision Embed │
├─────────────┤ ├─────────────┤ ├──────────────┤
│ 语音输入 │ ──→ │ Audio Enc │ ──→ │ Audio Embed │
└─────────────┘ └─────────────┘ └──────┬───────┘
↓
┌──────────────┐
│ 统一Embed │
└──────┬───────┘
↓
┌──────────────┐
│ Language Model│
└──────────────┘我觉得omni这里的图就很经典,很好的展示了特征向量拼接的过程
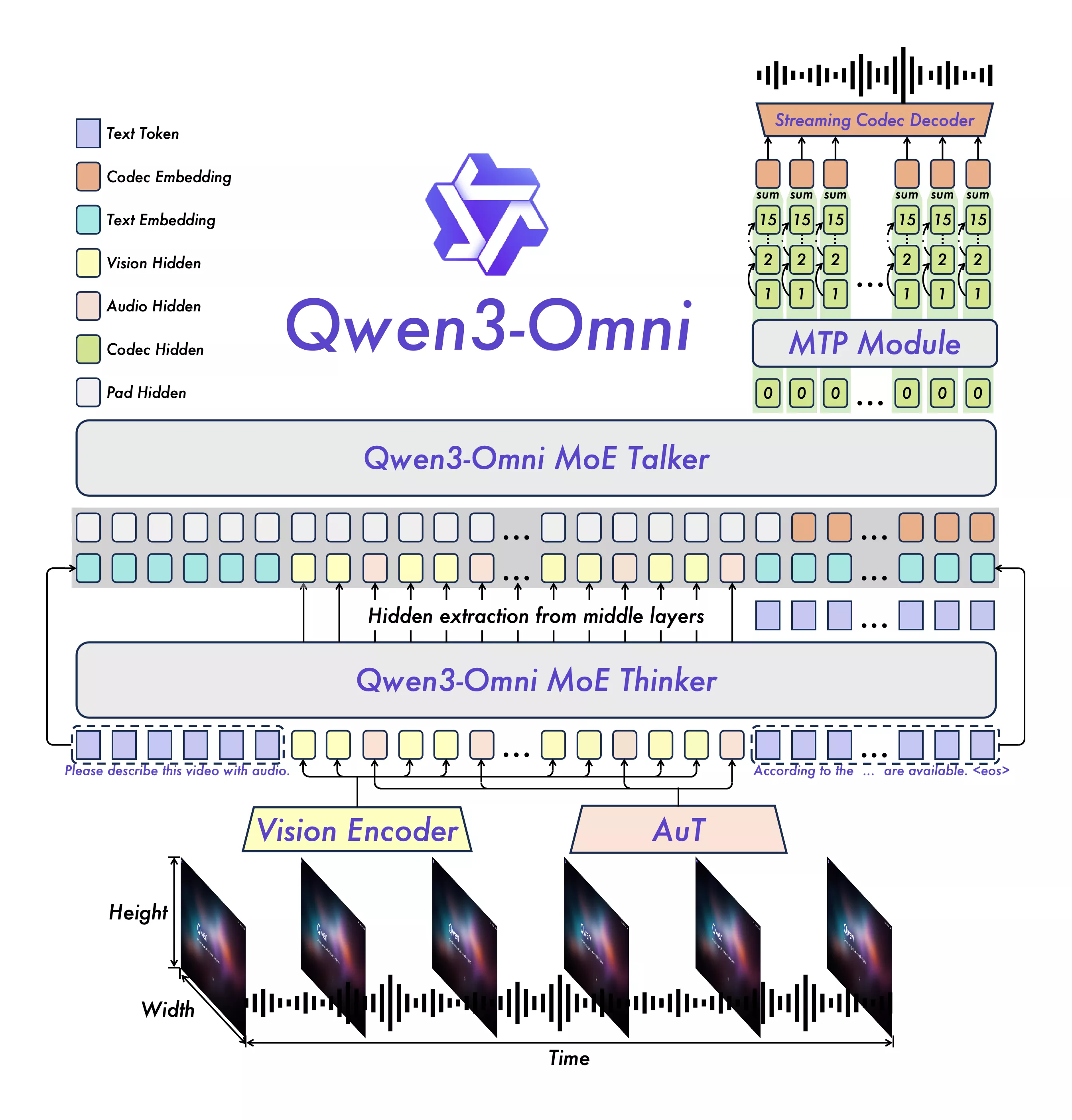
架构设计
文本模型 vs 多模态模型
| 组件 | 文本模型 (LLaMA) | 多模态模型 (LLaVA) |
|---|---|---|
| 输入 | 仅文本 | 文本 + 图像 |
| Tokenizer | get_tokenizer() |
get_processor() |
| 模型结构 | 单一 LlamaForCausalLM |
三组件架构 |
| 推理流程 | 统一流程 | EXTEND融合视觉,DECODE走文本 |
LLaVA 的三组件架构
1
2
3
4
5
6
7
8
9
10
11
class LlavaLlamaForCausalLM(nn.Module):
def __init__(self, config, linear_method=None):
super().__init__()
# 组件1: 视觉编码器 - CLIP Vision Model
self.vision_tower = None # 延迟加载
# 组件2: 多模态投影层 - 将视觉特征映射到文本空间
self.multi_modal_projector = LlavaMultiModalProjector(config)
# 组件3: 语言模型 - 标准的LLaMA
self.language_model = LlamaForCausalLM(config, linear_method)设计精髓:完全解耦的架构,语言模型无需修改即可复用。
初始化流程
模型识别
1
2
3
4
5
6
# python/sglang/srt/utils.py:123
def is_multimodal_model(model):
if isinstance(model, str):
return "llava" in model
if isinstance(model, ModelConfig):
return "llava" in model.path.lower()TokenizerManager 初始化
多模态模型和文本模型的第一个分叉点:
1
2
3
4
5
6
7
8
9
10
if is_multimodal_model(self.model_path):
# 多模态模型:加载 processor (tokenizer + image_processor)
self.processor = get_processor(...)
self.tokenizer = self.processor.tokenizer
# 使用进程池处理图像(避免GIL)
self.executor = concurrent.futures.ProcessPoolExecutor(...)
else:
# 文本模型:只加载 tokenizer
self.tokenizer = get_tokenizer(...)关键差异:
- 文本模型:
tokenizer只处理文本 - 多模态模型:
processor包含tokenizer+image_processor
权重加载
1
2
3
4
5
6
7
8
9
10
11
def load_weights(self, model_name_or_path, ...):
# 阶段1: 加载 CLIP 视觉模型
self.vision_tower = CLIPVisionModel.from_pretrained(vision_path).cuda()
# 计算图像特征长度
self.image_feature_len = int((self.image_size / self.patch_size) ** 2)
# 例如: (336 / 14)² = 24² = 576 个 patch tokens
# 阶段2: 加载多模态投影层权重
# 阶段3: 加载语言模型权重
self.language_model.load_weights(...)推理流程
整体流程
1
输入阶段 → Router处理 → EXTEND阶段(融合视觉特征) → DECODE阶段(文本生成)EXTEND 阶段:视觉特征融合
这是多模态推理的核心步骤:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# LlavaLlamaForCausalLM.forward() - EXTEND模式
# Step 1: 文本嵌入
input_embeds = self.language_model.model.embed_tokens(input_ids)
# Step 2: 视觉特征提取
image_outputs = self.vision_tower(pixel_values_tensor)
selected_image_feature = image_outputs.hidden_states[layer]
# Step 3: 视觉特征投影 (关键!)
image_features = self.multi_modal_projector(selected_image_feature)
# [num_images, num_patches, text_hidden_size]
# Step 4: 特征融合 (核心!)
for i in range(bs):
# 直接替换图像占位token的嵌入为视觉特征
input_embeds[start_idx + offset : start_idx + offset + pad_len] = image_features[i]
# Step 5: 语言模型推理
return self.language_model(input_embeds, positions, metadata, skip_embed=True)DECODE 阶段:文本生成
1
2
3
4
# LlavaLlamaForCausalLM.forward() - DECODE模式
# 解码阶段不再处理图像,直接走文本模型的标准流程
return self.language_model(input_ids, positions, metadata, skip_embed=False)原因:视觉信息已经通过 EXTEND 阶段融入 KV Cache,后续生成无需再处理图像。
Token 序列变化
1
2
3
4
5
6
7
8
9
10
11
# 原始文本
text = "USER: <image> What's this?"
# Tokenization
input_ids = [101, 102, 103, 32000, 104, 105, ...]
# ↑
# <image> 特殊token
# 调用 pad_input_ids() 展开
new_input_ids = [101, 102, 103, PAD0, PAD1, ..., PAD575, 104, 105, ...]
# ↑←─ 576个PAD tokens ──→↑为什么要 PAD?
- 占位:为图像特征预留空间
- 对齐:确保位置编码正确
- 缓存:通过 image_hash 实现特征缓存,避免重复处理
扩展新模型
必需组件
1. 模型注册
1
2
def is_multimodal_model(model):
return "llava" in model or "your_model" in model2. Chat Template
1
2
3
4
register_conv_template(Template(
name="your_model",
roles=("user", "assistant"),
))3. 多模态处理器
1
2
3
4
class YourModelMultimodalProcessor(BaseMultimodalProcessor):
def process_image(self, image_data):
# 实现图像预处理
pass4. Token 扩展函数
1
2
3
def pad_input_ids(self, input_ids, pad_value, **kwargs):
# 将 <image> token 展开为 N 个 PAD tokens
return new_input_ids, offset5. 视觉特征提取
1
2
3
4
def get_image_feature(self, pixel_values):
vision_outputs = self.vision_tower(pixel_values)
image_features = self.multi_modal_projector(vision_outputs)
return image_features实现流程
添加新多模态模型的步骤:
- 理解模型架构
- 视觉编码器:CLIP / SigLIP / 自定义
- 投影层:MLP / Q-Former
- 语言模型:LLaMA / Qwen2
- 实现 Processor
- 处理多模态输入数据
- 实现模型类
load_weights():加载权重pad_input_ids():Token 展开get_image_feature():特征提取forward():EXTEND 融合 + DECODE 推理
- 适配 Attention(如需要)
- 将 ViT 的 Attention 替换为 VisionAttention
- 注册和测试
总结
核心思想
多模态模型推理的核心是在嵌入层进行特征融合,语言模型本身无需感知输入来源。
关键差异
| 维度 | 文本模型 | 多模态模型 |
|---|---|---|
| 初始化 | tokenizer |
processor |
| 模型结构 | 单一 LM | Vision + Projector + LM |
| Token序列 | 固定 | 需要展开多模态 tokens |
| 嵌入构建 | 直接 embed_tokens() |
文本嵌入 + 视觉特征替换 |
| 推理路径 | 统一路径 | EXTEND融合,DECODE走文本 |
最佳实践
- 解耦设计:视觉编码器和语言模型完全独立
- 特征缓存:通过 image_hash 避免重复处理相同图像
- 并行处理:使用进程池处理图像,避免 GIL
- 路径复用:DECODE 阶段完全复用文本模型逻辑



评论
匿名评论隐私政策






