4-sglang中的内存池

4-sglang中的内存池
gogongxt在sglang中,对内存的管理总共分成了三个核心组件
- RadixTree
- ReqToTokenPool
- TokenToKVPool
三个的大概结构如下图所示:
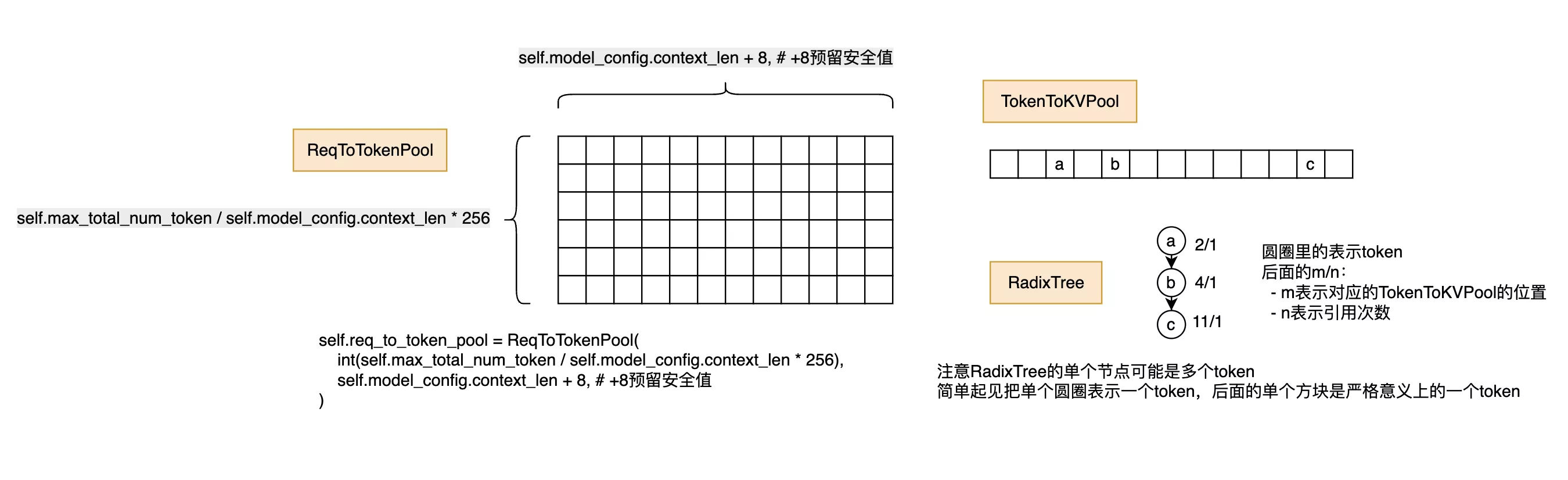
- RadixTree 前缀树,用户匹配请求的前缀,对应到vllm的paged attention的page结构
- ReqToTokenPool 请求和token的对应表,每个请求一行数据,列表示第k个token对应到TokenToKVPool的id
- TokenToKVPool token对应到kvcache的id,是一个一维超长数组,size大小就是系统存储的kvcache tokens的总数
依靠这三个组件,相互配合就可以完成对请求的kvcache内存管理
组件使用
我们从请求调度流程的视角,看一下三大组件是怎么管理一个请求的内存声明周期的
首先是来了请求,需要在RadixTree做前缀匹配
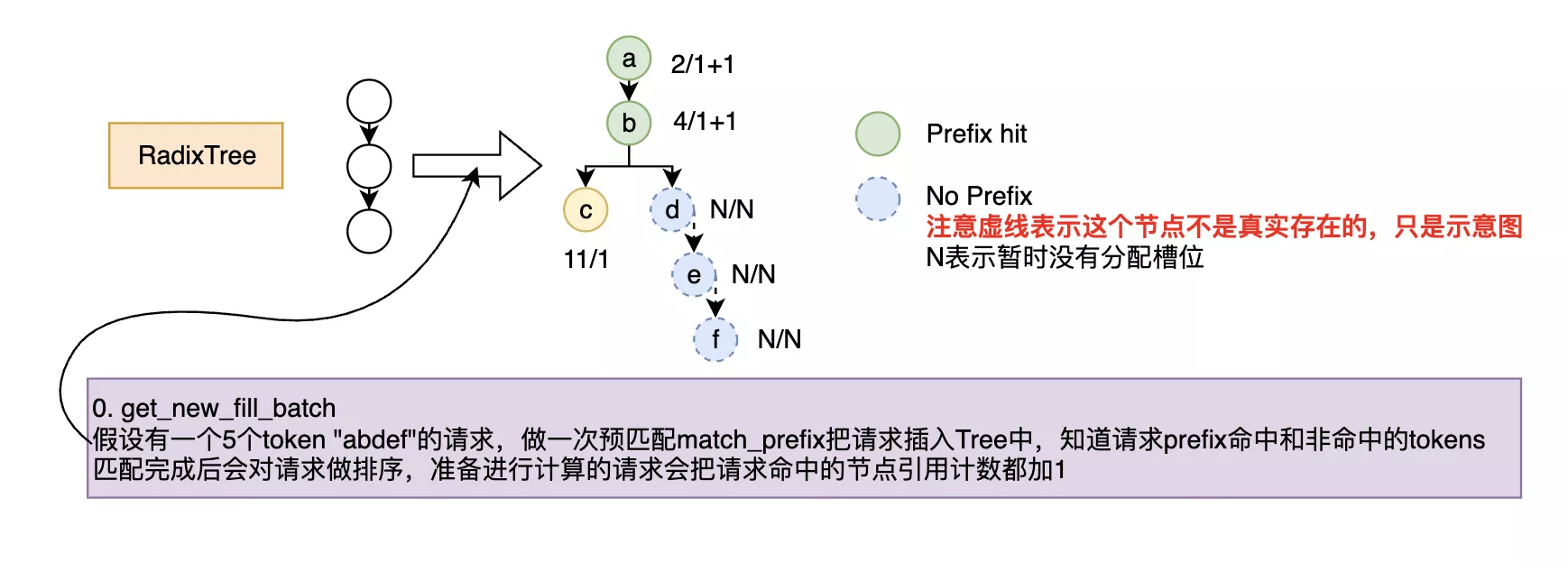
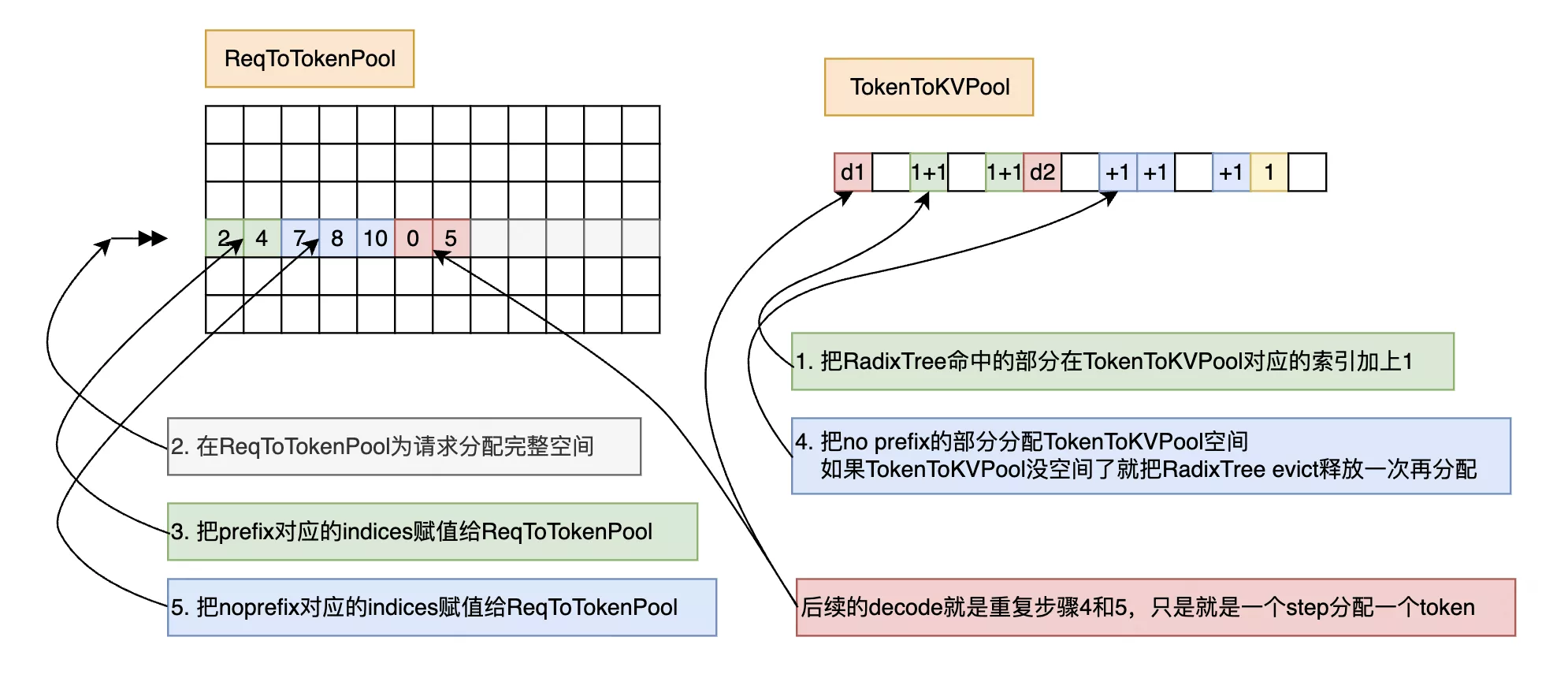
做Prefill和Decode
请求完成后需要清空内存(减少引用计数,只有内存不够时才真的清除)
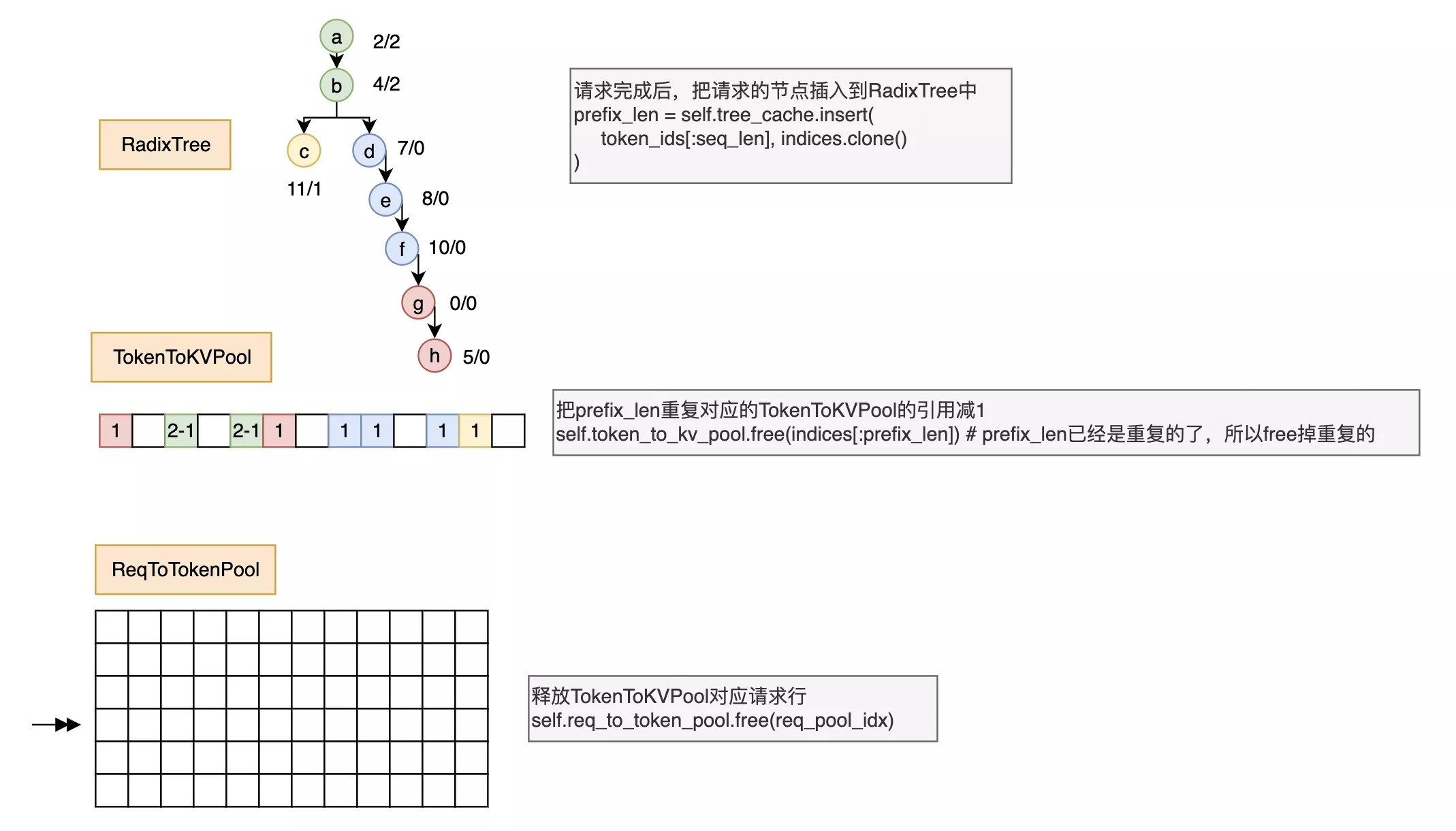

可以观察到,一个请求最后计算完成的状态下,相比计算前,三大组件的状态发生了以下改变:
- ReqToTokenPool没有发生改变,清空了所有内容
- 新增了请求没有命中和decode产生的内存,并且这些引用都是1
- RadixTree和类似TokenToKVPool,新增了请求没有命中和decode产生的节点,并且这些新的节点引用计数都是0
细节补充
内存不够时evict
当显存不够,无法分配新的Token时,就会释放内存,具体代码为:
1
2
3
4out_cache_loc = self.token_to_kv_pool.alloc(extend_num_tokens) # 尝试分配内存 if out_cache_loc is None: # 空间不够,分配内存失败 self.tree_cache.evict(extend_num_tokens, self.token_to_kv_pool.free) # 从tree_cache的叶子节点开始,删除引用计数为0的节点,并且把节点对应的token_to_kv_pool的引用计数也减1(会减到0) out_cache_loc = self.token_to_kv_pool.alloc(extend_num_tokens) # 因为有token_to_kv_pool有新的引用为0的token了,就可以分配出新的了具体来说就是根据LRU看一下RadixTree哪些节点的引用是0,就弹出对应节点,节点对应的indices通过
self.token_to_kv_pool.free进行释放对于token_to_kv_pool来说,free也是减少引用计数,计数减少到0,就认为是可以用的了
组件源码
RadixTree
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
class TreeNode:
def __init__(self):
self.children = defaultdict(TreeNode)
self.parent = None
self.value = None
self.ref_counter = 0
self.last_access_time = time.time()
def __lt__(self, other):
return self.last_access_time < other.last_access_time
def match(key, seq):
i = 0
for k, w in zip(key, seq):
if k != w:
break
i += 1
return i
class RadixCache:
def __init__(self, disable=False):
self.root_node = TreeNode()
self.root_node.value = []
self.root_node.ref_counter = 1
self.evictable_size_ = 0
self.disable = disable
##### Public API #####
# 返回为匹配到的前缀value和匹配到的最后一个节点,例如12345匹配到123,返回就是(123对应的token_to_kv_pool的索引,节点3)
def match_prefix(self, key):
if self.disable:
return [], self.root_node
value = []
last_node = [self.root_node]
self._match_prefix_helper(self.root_node, key, value, last_node)
if value:
value = torch.concat(value)
return value, last_node[0]
def insert(self, key, value=None):
if self.disable:
return len(key)
if value is None:
value = [x for x in key]
return self._insert_helper(self.root_node, key, value)
def pretty_print(self):
self._print_helper(self.root_node, 0)
print(f"#tokens: {self.total_size()}")
def total_size(self):
return self._total_size_helper(self.root_node)
def evict(self, num_tokens, evict_callback):
if self.disable:
raise RuntimeError()
leaves = self._collect_leaves()
heapq.heapify(leaves)
num_evicted = 0
while num_evicted < num_tokens and len(leaves):
x = heapq.heappop(leaves)
if x == self.root_node:
break
if x.ref_counter > 0:
continue
num_evicted += evict_callback(x.value)
self._delete_leaf(x)
if len(x.parent.children) == 0:
heapq.heappush(leaves, x.parent)
def inc_ref_counter(self, node):
delta = 0
# 从请求的最后一个节点往前遍历
while node != self.root_node:
if node.ref_counter == 0:
self.evictable_size_ -= len(node.value)
delta -= len(node.value)
node.ref_counter += 1
node = node.parent
return delta
def dec_ref_counter(self, node):
delta = 0
# 从请求的最后一个节点往前遍历
while node != self.root_node:
if node.ref_counter == 1:
self.evictable_size_ += len(node.value)
delta += len(node.value)
node.ref_counter -= 1
node = node.parent
return delta
def evictable_size(self):
# 也就是那些ref_counter==0的节点的value
return self.evictable_size_
##### Internal Helper Functions #####
def _match_prefix_helper(self, node, key, value, last_node):
node.last_access_time = time.time()
for c_key, child in node.children.items():
prefix_len = match(c_key, key)
if prefix_len != 0:
if prefix_len < len(c_key):
new_node = self._split_node(c_key, child, prefix_len)
value.append(new_node.value)
last_node[0] = new_node
else:
value.append(child.value)
last_node[0] = child
self._match_prefix_helper(child, key[prefix_len:], value, last_node)
break
def _split_node(self, key, child, split_len):
# new_node -> child
new_node = TreeNode()
new_node.children = {key[split_len:]: child}
new_node.parent = child.parent
new_node.ref_counter = child.ref_counter
new_node.value = child.value[:split_len]
child.parent = new_node
child.value = child.value[split_len:]
new_node.parent.children[key[:split_len]] = new_node
del new_node.parent.children[key]
return new_node
def _insert_helper(self, node, key, value):
node.last_access_time = time.time()
for c_key, child in node.children.items():
prefix_len = match(c_key, key)
if prefix_len == len(c_key):
if prefix_len == len(key):
return prefix_len
else:
key = key[prefix_len:]
value = value[prefix_len:]
return prefix_len + self._insert_helper(child, key, value)
if prefix_len:
new_node = self._split_node(c_key, child, prefix_len)
return prefix_len + self._insert_helper(
new_node, key[prefix_len:], value[prefix_len:]
)
if len(key):
new_node = TreeNode()
new_node.parent = node
new_node.value = value
node.children[key] = new_node
self.evictable_size_ += len(value)
return 0
def _print_helper(self, node, indent):
for key, child in node.children.items():
print(" " * indent, len(key), key[:10], f"r={child.ref_counter}")
self._print_helper(child, indent=indent + 2)
def _delete_leaf(self, node):
for k, v in node.parent.children.items():
if v == node:
break
del node.parent.children[k]
self.evictable_size_ -= len(k)
def _total_size_helper(self, node):
x = len(node.value)
for child in node.children.values():
x += self._total_size_helper(child)
return x
def _collect_leaves(self):
ret_list = []
def dfs_(cur_node):
if len(cur_node.children) == 0:
ret_list.append(cur_node)
for x in cur_node.children.values():
dfs_(x)
dfs_(self.root_node)
return ret_listReqToTokenPool
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
class ReqToTokenPool:
def __init__(self, size, max_context_len):
# mem_state为1表示可以用,为0表示被占用,理论上为1的数量等于can_use_mem_size
self.mem_state = torch.ones((size,), dtype=torch.bool, device="cuda")
self.can_use_mem_size = size
self.req_to_token = torch.empty(
(size, max_context_len), dtype=torch.int32, device="cuda"
)
def alloc(self, need_size):
if need_size > self.can_use_mem_size:
return None
available_indices = torch.nonzero(self.mem_state)
if available_indices.numel() == 0:
return None
select_index = available_indices.squeeze(1)[:need_size]
if select_index.numel() == 0:
return None
self.mem_state[select_index] = 0
self.can_use_mem_size -= need_size
return select_index.to(torch.int32)
def free(self, free_index):
if isinstance(free_index, (int,)):
# Clamp individual integer indices
free_index = max(0, min(free_index, len(self.mem_state) - 1))
self.can_use_mem_size += 1
else:
if len(free_index) == 0:
return
# Clamp tensor indices to prevent out of bounds access
free_index = torch.clamp(free_index, 0, len(self.mem_state) - 1)
self.can_use_mem_size += free_index.shape[0]
self.mem_state[free_index] = 1TokenToKVPool
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
class TokenToKVPool:
def __init__(self, size, dtype, head_num, head_dim, layer_num):
# 值为0表示是可以用,大于0表示被引用次数,不可用,注意和上面的区分开来,含义是反的
self.mem_state = torch.zeros((size,), dtype=torch.int16, device="cuda")
self.alloc_ct = 0
# 实际分配内存
# [size, key/value, head_num, head_dim] for each layer
self.kv_data = [
torch.empty((size, 2, head_num, head_dim), dtype=dtype, device="cuda")
for _ in range(layer_num)
]
def get_key_buffer(self, layer_id):
return self.kv_data[layer_id][:, 0]
def get_value_buffer(self, layer_id):
return self.kv_data[layer_id][:, 1]
def alloc(self, need_size):
available_indices = torch.nonzero(self.mem_state == 0)
if available_indices.numel() == 0:
return None
select_index = available_indices.squeeze(1)[:need_size]
if select_index.numel() < need_size:
return None
self.add_refs(select_index)
return select_index.to(torch.int32)
# 可以先不关注下面的,事实上sglang现在也不是分配连续内存,普通的alloc够用了,下里的代码还有问题
def alloc_contiguous(self, need_size):
available_indices = torch.nonzero(self.mem_state == 0)
if available_indices.numel() == 0:
return None
empty_index = available_indices.squeeze(1)[:need_size]
if empty_index.numel() < need_size:
return None
empty_size = len(empty_index)
loc_sum = (
empty_index[need_size - 1 :] - empty_index[: empty_size - (need_size - 1)]
)
can_used_loc = empty_index[: empty_size - (need_size - 1)][
loc_sum == need_size - 1
]
if can_used_loc.shape[0] == 0:
return None
start_loc = can_used_loc[0].item()
select_index = torch.arange(start_loc, start_loc + need_size, device="cuda")
self.add_refs(select_index)
return select_index.to(torch.int32), start_loc, start_loc + need_size
def free(self, free_index):
return self.decrease_refs(free_index)
def available_size(self):
return torch.sum(self.mem_state == 0).item()
def add_refs(self, token_index: torch.Tensor):
if len(token_index) == 0:
return
# Clamp indices to prevent out of bounds access
token_index = torch.clamp(token_index, 0, len(self.mem_state) - 1)
self.alloc_ct += len(token_index)
self.mem_state[token_index] += 1
def decrease_refs(self, token_index: torch.Tensor):
if len(token_index) == 0:
return 0
# Clamp indices to prevent out of bounds access
token_index = torch.clamp(token_index, 0, len(self.mem_state) - 1)
self.alloc_ct -= len(token_index)
self.mem_state[token_index] -= 1
num_freed = torch.sum(self.mem_state[token_index] == 0)
# if self.alloc_ct == 0:
# print(f"TokenToKVPool: freed all. size = {len(self.mem_state)}.")
return num_freed


喜欢这篇文章的人也看了

评论
匿名评论隐私政策






