sglang-attention

sglang-attention
gogongxt以nano-sglang举例子
下面以llama2-7b来说,apply*chat_template是在开头加上<s>*
输入”12345” 就是 <s>_12345,对应input_ids是[1,
29871, 29896, 29906, 29941, 29946, 29945]
prefill
我们第一遍先发送”12345”,那么[1, 29871, 29896, 29906, 29941, 29946, 29945]就会被cache住
第二遍发送”1234512345”,就是cache了7个token,要extend5个
req.input_ids = [1, 29871, 29896, 29906, 29941, 29946, 29945, 29896, 29906, 29941, 29946, 29945]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
@torch.inference_mode()
def forward_extend(
self,
input_ids,
req_pool_indices,
seq_lens,
prefix_lens,
out_cache_loc,
return_normalized_logprob,
):
input_metadata = InputMetadata.create(
self,
forward_mode=ForwardMode.EXTEND,
tp_size=self.tp_size,
req_pool_indices=req_pool_indices, # [0] 表示请求在req_pool的位置,size是请求数
seq_lens=seq_lens, # [12] 表示请求的长度,size是请求数
prefix_lens=prefix_lens, # [7] 表示请求cache tokens个数,size是请求数
out_cache_loc=out_cache_loc, # [16, 17, 18, 19, 20] 新增加的token的kvcache放的位置,size是batch out tokens个数
return_normalized_logprob=return_normalized_logprob, # 一般是False,是否需要返回token的logprob
)
return self.model.forward(input_ids, input_metadata.positions, input_metadata)
```python
@dataclass
class InputMetadata:
model_runner: "ModelRunner"
forward_mode: ForwardMode
batch_size: int
total_num_tokens: int
max_seq_len: int
req_pool_indices: torch.Tensor
start_loc: torch.Tensor
seq_lens: torch.Tensor
prefix_lens: torch.Tensor
positions: torch.Tensor
req_to_token_pool: ReqToTokenPool
token_to_kv_pool: TokenToKVPool
# for extend
extend_seq_lens: torch.Tensor = None
extend_start_loc: torch.Tensor = None
max_extend_len: int = 0
out_cache_loc: torch.Tensor = None
out_cache_cont_start: torch.Tensor = None
out_cache_cont_end: torch.Tensor = None
other_kv_index: torch.Tensor = None
return_normalized_logprob: bool = False
def init_extend_args(self):
self.extend_seq_lens = self.seq_lens - self.prefix_lens
self.extend_start_loc = torch.zeros_like(self.seq_lens)
self.extend_start_loc[1:] = torch.cumsum(self.extend_seq_lens[:-1], 0)
self.max_extend_len = int(torch.max(self.extend_seq_lens))
@classmethod
def create(
cls,
model_runner,
tp_size,
forward_mode,
req_pool_indices,
seq_lens,
prefix_lens,
out_cache_loc,
out_cache_cont_start=None,
out_cache_cont_end=None,
return_normalized_logprob=False,
):
batch_size = len(req_pool_indices) # 1 就是bs
start_loc = torch.zeros((batch_size,), dtype=torch.int32, device="cuda")
start_loc[1:] = torch.cumsum(seq_lens[:-1], dim=0) # seqa_lens tokens个数前缀和
total_num_tokens = int(torch.sum(seq_lens)) # 12 总tokens个数
max_seq_len = int(torch.max(seq_lens)) # 12 最大值
if forward_mode == ForwardMode.DECODE:
positions = (seq_lens - 1).to(torch.int64)
other_kv_index = model_runner.req_to_token_pool.req_to_token[
req_pool_indices[0], seq_lens[0] - 1
].item()
else:
seq_lens_np = seq_lens.cpu().numpy()
prefix_lens_np = prefix_lens.cpu().numpy()
positions = torch.tensor(
np.concatenate(
[
np.arange(
prefix_lens_np[i],
seq_lens_np[i],
)
for i in range(batch_size)
],
axis=0,
),
device="cuda",
) # [7,8,9,10,11] positions用于后面推理时的位置编码
other_kv_index = None
ret = cls(
model_runner=model_runner,
forward_mode=forward_mode,
batch_size=batch_size,
total_num_tokens=total_num_tokens,
max_seq_len=max_seq_len,
req_pool_indices=req_pool_indices,
start_loc=start_loc,
seq_lens=seq_lens,
prefix_lens=prefix_lens,
positions=positions,
req_to_token_pool=model_runner.req_to_token_pool,
token_to_kv_pool=model_runner.token_to_kv_pool,
out_cache_loc=out_cache_loc,
out_cache_cont_start=out_cache_cont_start,
out_cache_cont_end=out_cache_cont_end,
return_normalized_logprob=return_normalized_logprob,
other_kv_index=other_kv_index,
)
if forward_mode == ForwardMode.EXTEND:
ret.init_extend_args()
ret.use_flashinfer = "flashinfer" in model_runner.model_mode
if ret.use_flashinfer:
ret.init_flashinfer_args(tp_size)
return ret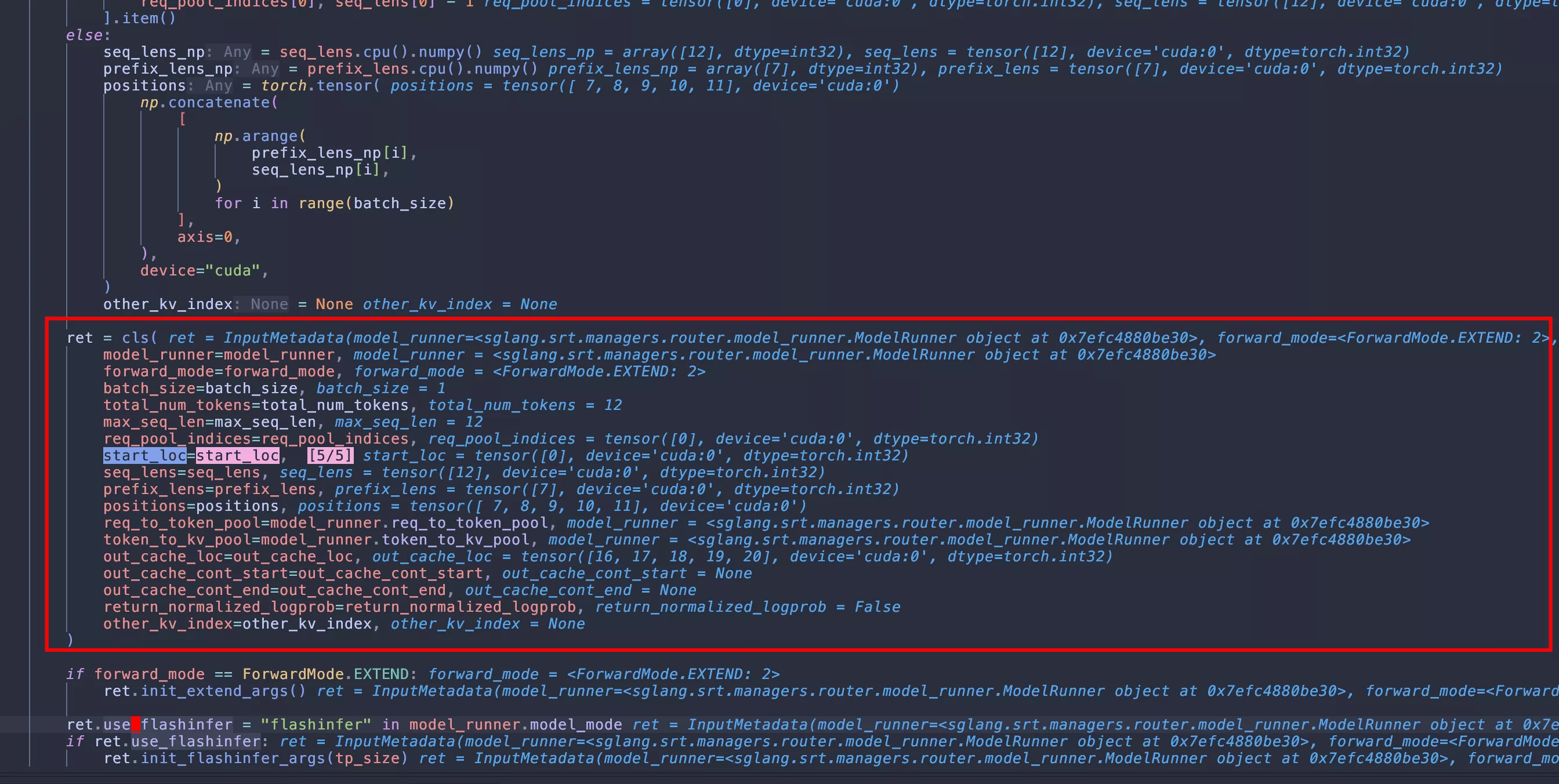
下面举一个两个请求的例子,讲的更清楚一些
1
2
3
4
5
6
7
8
9
10
11
prompts = [
"The capital of France is",
"Today is a sunny day and I like",
]
cut_num = [3, 4]
reqs = []
for i in range(len(prompts)):
req = Req(i)
req.input_ids = tokenizer.encode(prompts[i])[: cut_num[i]]
req.sampling_params = sampling_params
reqs.append(req)两个请求:
- 第一个算上chat_template是6个,这里cache了3个,也就是要extend 3个
- 第二个算上chat_template是10个token,这里cache了4个,也就是要extend 6个
extend代码extend_forward_triton:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
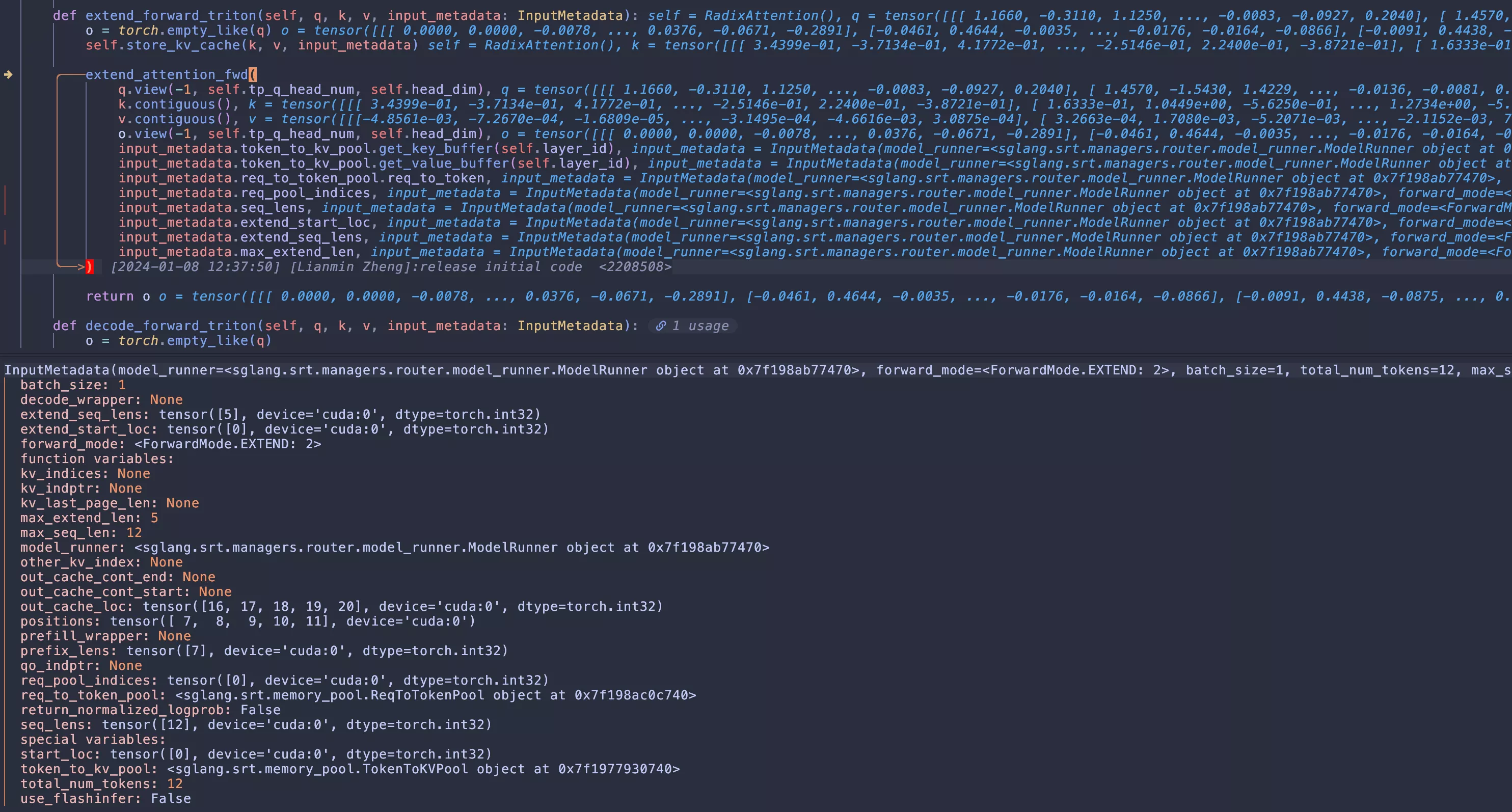
def extend_forward_triton(self, q, k, v, input_metadata: InputMetadata):
o = torch.empty_like(q)
self.store_kv_cache(k, v, input_metadata)
extend_attention_fwd(
q.view(-1, self.tp_q_head_num, self.head_dim),
k.contiguous(),
v.contiguous(),
o.view(-1, self.tp_q_head_num, self.head_dim),
input_metadata.token_to_kv_pool.get_key_buffer(self.layer_id), # 因为上一步store_kv_cache已经存储了,所以这里的就是完整的kvcache
input_metadata.token_to_kv_pool.get_value_buffer(self.layer_id), # 因为上一步store_kv_cache已经存储了,所以这里的就是完整的kvcache
input_metadata.req_to_token_pool.req_to_token,
input_metadata.req_pool_indices,
input_metadata.seq_lens,
input_metadata.extend_start_loc,
input_metadata.extend_seq_lens,
input_metadata.max_extend_len,
)
return o首先是创建一个和q相同shape的o预分配好输出
然后是存储kvcache,因为在计算attention之前已经计算好了kv,这里就把kvcache存储到对应的kvpool对应的索引中
1
2
3
4
5
6def store_kv_cache(self, cache_k, cache_v, input_metadata: InputMetadata): key_buffer = input_metadata.token_to_kv_pool.get_key_buffer(self.layer_id) # 返回的是当前layer的大buffer张量的引用 value_buffer = input_metadata.token_to_kv_pool.get_value_buffer(self.layer_id) # 返回的是当前layer的大buffer张量的引用 if input_metadata.out_cache_loc is not None: key_buffer[input_metadata.out_cache_loc] = cache_k # 在这里对应把内存存储到索引位置就可以了 value_buffer[input_metadata.out_cache_loc] = cache_v # 在这里对应把内存存储到索引位置就可以了调用kernel推理extend_attention_fwd,下面接着讲这个函数
InputMetadata的详细内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
InputMetadata(model_runner=<sglang.srt.managers.router.model_runner.ModelRunner object at 0x7f599dbebd40>, forward_mode=<ForwardMode.EXTEND: 1>, batch_size=2, total_num_tokens=16, max_seq_len=10, req_pool_indices=tensor([2, 3], device='cuda:0', dtype=torch.int32), start_loc=tensor([0, 6], device='cuda:0', dtype=torch.int32), seq_lens=tensor([ 6, 10], device='cuda:0', dtype=torch.int32), prefix_lens=tensor([3, 4], device='cuda:0', dtype=torch.int32), positions=tensor([3, 4, 5, 4, 5, 6, 7, 8, 9], device='cuda:0'), req_to_token_pool=<sglang.srt.memory_pool.ReqToTokenPool object at 0x7f599fd3d460>, token_to_kv_pool=<sglang.srt.memory_pool.TokenToKVPool object at 0x7f5c2c567b00>, extend_seq_lens=tensor([3, 6], device='cuda:0', dtype=torch.int32), extend_start_loc=tensor([0, 3], device='cuda:0', dtype=torch.int32), max_extend_len=6, out_cache_loc=tensor([ 7, 8, 9, 10, 11, 12, 13, 14, 15], device='cuda:0',\n dtype=torch.int32), out_cache_cont_start=None, out_cache_cont_end=None, other_kv_index=None, return_normalized_logprob=False, use_flashinfer=False, qo_indptr=None, kv_indptr=None, kv_indices=None, kv_last_page_len=None)
batch_size: 2
decode_wrapper: None
extend_seq_lens: tensor([3, 6], device='cuda:0', dtype=torch.int32)
extend_start_loc: tensor([0, 3], device='cuda:0', dtype=torch.int32)
forward_mode: <ForwardMode.EXTEND: 1>
function variables:
kv_indices: None
kv_indptr: None
kv_last_page_len: None
max_extend_len: 6
max_seq_len: 10
model_runner: <sglang.srt.managers.router.model_runner.ModelRunner object at 0x7f599dbebd40>
other_kv_index: None
out_cache_cont_end: None
out_cache_cont_start: None
out_cache_loc: tensor([ 7, 8, 9, 10, 11, 12, 13, 14, 15], device='cuda:0',\n dtype=torch.int32)
positions: tensor([3, 4, 5, 4, 5, 6, 7, 8, 9], device='cuda:0')
prefill_wrapper: None
prefix_lens: tensor([3, 4], device='cuda:0', dtype=torch.int32)
qo_indptr: None
req_pool_indices: tensor([2, 3], device='cuda:0', dtype=torch.int32)
req_to_token_pool: <sglang.srt.memory_pool.ReqToTokenPool object at 0x7f599fd3d460>
return_normalized_logprob: False
seq_lens: tensor([ 6, 10], device='cuda:0', dtype=torch.int32)
special variables:
start_loc: tensor([0, 6], device='cuda:0', dtype=torch.int32)
token_to_kv_pool: <sglang.srt.memory_pool.TokenToKVPool object at 0x7f5c2c567b00>
total_num_tokens: 16
use_flashinfer: False调用kernel extend_attention_fwd
详细代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
def extend_attention_fwd(
q_extend, # shape: ([9, 32, 64])
k_extend, # shape: ([9, 4, 64])
v_extend, # shape: ([9, 4, 64])
o_extend, # shape: ([9, 32, 64])
k_buffer, # shape: ([2904745, 4, 64])
v_buffer, # shape: ([2904745, 4, 64])
req_to_tokens, # shape: ([363093, 2056])
b_req_idx, # shape: ([2]) value: [2,3] # 对应到req_to_tokens的索引
b_seq_len, # shape: ([2]) value: [6,10] # 每个请求的总长
b_start_loc_extend, # shape: ([2]) value: [0, 3] # 每个请求extend的起始kvcache loc索引
b_seq_len_extend, # shape: ([2]) value: [3, 6] # 每个请求要计算extend的长度
max_len_extend, # value: 6
):
"""
q_extend, k_extend, v_extend, o_extend: contiguous tensors
k_buffer, v_buffer: (prefix + extend) tensors in mem_manager
"""
BLOCK_M, BLOCK_N = 128, 128
Lq, Lk, Lv, Lo = ( # 都是64
q_extend.shape[-1],
k_extend.shape[-1],
v_extend.shape[-1],
o_extend.shape[-1],
)
assert Lq == Lk and Lk == Lv and Lv == Lo
assert Lq in {16, 32, 64, 128}
sm_scale = 1.0 / (Lq**0.5) # 提前算出每个头计算qk除上的值 value=0.125
batch_size, head_num = b_seq_len.shape[0], q_extend.shape[1] # 2, 32
kv_group_num = q_extend.shape[1] // k_extend.shape[1] # 8=32/4 也就是有4组,每组对应8个q头
grid = (batch_size, head_num, triton.cdiv(max_len_extend, BLOCK_M)) # grid=(2, 32, 1)
num_warps = 4 if Lk <= 64 else 8 # num_warps=4
num_stages = 1
_fwd_kernel[grid](
q_extend,
k_extend,
v_extend,
o_extend,
k_buffer,
v_buffer,
req_to_tokens,
b_req_idx,
b_seq_len,
b_start_loc_extend,
b_seq_len_extend,
sm_scale,
kv_group_num,
q_extend.stride(0),
q_extend.stride(1),
k_extend.stride(0),
k_extend.stride(1),
v_extend.stride(0),
v_extend.stride(1),
o_extend.stride(0),
o_extend.stride(1),
k_buffer.stride(0),
k_buffer.stride(1),
v_buffer.stride(0),
v_buffer.stride(1),
req_to_tokens.stride(0),
BLOCK_DMODEL=Lq,
BLOCK_M=BLOCK_M,
BLOCK_N=BLOCK_N,
num_warps=num_warps,
num_stages=num_stages,
)计算triton kernel分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
@triton.jit
def _fwd_kernel(
Q_Extend, # shape: ([9, 32, 64])
K_Extend, # shape: ([9, 4, 64])
V_Extend, # shape: ([9, 4, 64])
O_Extend, # shape: ([9, 32, 64])
K_Buffer, # shape: ([2904745, 4, 64])
V_Buffer, # shape: ([2904745, 4, 64])
Req_to_tokens, # shape: ([363093, 2056])
B_req_idx, # shape: ([2]) value: [2,3] # 对应到req_to_tokens的索引
B_Seq_Len, # shape: ([2]) value: [6,10] # 每个请求的总长
B_Start_Loc_Extend, # shape: ([2]) value: [0, 3] # 每个请求extend的起始kvcache loc索引
B_Seq_Len_Extend, # shape: ([2]) value: [3, 6] # 每个请求要计算extend的长度
sm_scale, # 0.125
kv_group_num, # 8
stride_qbs, # 2048
stride_qh, # 64
stride_kbs, # 256
stride_kh, # 64
stride_vbs, # 256
stride_vh, # 64
stride_obs, # 2048
stride_oh, # 64
stride_buf_kbs, # 512
stride_buf_kh, # 64
stride_buf_vbs, # 512
stride_buf_vh, # 64
stride_req_to_tokens_b, # 2056
BLOCK_DMODEL: tl.constexpr, # 64
BLOCK_M: tl.constexpr, # 128
BLOCK_N: tl.constexpr, # 128
):
# ==================== 程序 ID 初始化 ====================
# cur_seq: 当前处理的序列 ID(batch 中的第几个样本)
cur_seq = tl.program_id(0) # 0
# cur_head: 当前处理的注意力头 ID
cur_head = tl.program_id(1) # 0
# cur_block_m: 当前处理的 Q 块 ID(每个块包含 BLOCK_M 个 token)
cur_block_m = tl.program_id(2)
# cur_kv_head: 当前 KV 头 ID(用于 GQA/MQA,计算当前 Q 头对应的 KV 头)
cur_kv_head = cur_head // kv_group_num
# ==================== 加载序列长度信息 ====================
# cur_seq_len: 当前序列的总长度(prefix + extend)
cur_seq_len = tl.load(B_Seq_Len + cur_seq) # 6
# cur_seq_len_extend: 当前序列的 extend 部分长度(新生成的 token 数)
cur_seq_len_extend = tl.load(B_Seq_Len_Extend + cur_seq) # 3
# cur_seq_len_prefix: 当前序列的 prefix 部分长度(历史 KV 缓存中的 token 数)
cur_seq_len_prefix = cur_seq_len - cur_seq_len_extend # 3
# ==================== 加载位置索引信息 ====================
# cur_seq_prefix_start_in_loc: prefix 部分的起始位置(固定为 0)
cur_seq_prefix_start_in_loc = 0
# cur_seq_extend_start_contiguous: extend 部分在连续内存中的起始位置
cur_seq_extend_start_contiguous = tl.load(B_Start_Loc_Extend + cur_seq) # 0
# cur_batch_req_idx: 当前序列在 batch 中的请求 ID
cur_batch_req_idx = tl.load(B_req_idx + cur_seq) # 2
# ==================== 计算 Q 矩阵的偏移和加载 Q ====================
# offs_d: 生成维度索引 [0, 1, 2, ..., BLOCK_DMODEL-1]
offs_d = tl.arange(0, BLOCK_DMODEL)
# offs_m: 生成 M 维度索引 [0, 1, 2, ..., BLOCK_M-1]
offs_m = tl.arange(0, BLOCK_M)
# mask_m: 有效位置掩码,防止访问超出序列长度
mask_m = (cur_block_m * BLOCK_M + offs_m) < cur_seq_len_extend
# offs_q: 计算 Q 矩阵的内存偏移
# - cur_seq_extend_start_contiguous + cur_block_m * BLOCK_M + offs_m[:, None]: token 维度位置
# - stride_qbs: batch 维度的步长
# - cur_head * stride_qh: head 维度的步长
# - offs_d[None, :]: 特征维度偏移
offs_q = (
(cur_seq_extend_start_contiguous + cur_block_m * BLOCK_M + offs_m[:, None])
* stride_qbs
+ cur_head * stride_qh
+ offs_d[None, :]
)
# q: 加载 Q 矩阵的当前块,形状为 [BLOCK_M, BLOCK_DMODEL]
q = tl.load(Q_Extend + offs_q, mask=mask_m[:, None], other=0.0)
# ==================== Stage 1: 计算与 prefix 部分的注意力 ====================
# offs_n: 生成 N 维度索引 [0, 1, 2, ..., BLOCK_N-1],用于 K/V 的块迭代
offs_n = tl.arange(0, BLOCK_N)
# acc: 累加器,存储加权后的 V 值和,形状 [BLOCK_M, BLOCK_DMODEL]
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32)
# deno: 分母累加器,存储 softmax 分母,形状 [BLOCK_M]
deno = tl.zeros([BLOCK_M], dtype=tl.float32)
# e_max: 用于存储历史块的最大值
e_max = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf")
# 遍历 prefix 部分的所有 KV 块(每次处理 BLOCK_N 个 token)
for start_n in range(0, cur_seq_len_prefix, BLOCK_N):
# 确保 start_n 是 BLOCK_N 的倍数(Triton 优化要求)
start_n = tl.multiple_of(start_n, BLOCK_N)
# mask_n: prefix 部分的有效位置掩码
mask_n = (start_n + offs_n) < cur_seq_len_prefix
# offs_b_loc_prefix: 计算 Req_to_tokens 表的偏移
# - cur_batch_req_idx * stride_req_to_tokens_b: batch 偏移
# - cur_seq_prefix_start_in_loc + start_n + offs_n: token 位置
offs_b_loc_prefix = cur_batch_req_idx * stride_req_to_tokens_b + (
cur_seq_prefix_start_in_loc + start_n + offs_n
)
# offs_kv_loc: 从 Req_to_tokens 表加载实际的 KV 缓存位置索引
# Req_to_tokens 表将逻辑 token 位置映射到物理 KV 缓存位置(因为 KV 缓存是非连续的)
offs_kv_loc = tl.load(Req_to_tokens + offs_b_loc_prefix, mask=mask_n, other=0)
# load k in transposed way
# offs_buf_k: 计算 K_Buffer 的内存偏移
# - offs_kv_loc[None, :] * stride_buf_kbs: 根据物理位置索引计算 batch 维度偏移
# - cur_kv_head * stride_buf_kh: head 维度偏移
# - offs_d[:, None]: 特征维度偏移(转置布局)
offs_buf_k = (
offs_kv_loc[None, :] * stride_buf_kbs
+ cur_kv_head * stride_buf_kh
+ offs_d[:, None]
)
# k: 加载 K 矩阵的当前块,形状为 [BLOCK_DMODEL, BLOCK_N](转置布局)
k = tl.load(K_Buffer + offs_buf_k, mask=mask_n[None, :], other=0.0)
# qk: 初始化 QK 注意力分数矩阵,形状 [BLOCK_M, BLOCK_N]
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
# qk += tl.dot(q, k): 计算 Q 和 K 的点积(矩阵乘法)
qk += tl.dot(q, k)
# qk *= sm_scale: 应用缩放因子 1/sqrt(d_k),防止 softmax 梯度消失
qk *= sm_scale
# qk = tl.where(...): 应用掩码,将无效位置设为负无穷
# 在这里无效位置就是超出边界的位置,会设置成-inf,(e^(-inf)=0)就会是0
qk = tl.where(mask_m[:, None] & mask_n[None, :], qk, float("-inf"))
# ==================== Online Softmax 更新 ====================
# n_e_max: 更新后的最大值,取当前块的最大值和历史最大值的较大者
# tl.max(qk,1) 对qk在第一维取最大值,输出维度为[BLOCK_M]
n_e_max = tl.maximum(tl.max(qk, 1), e_max)
# re_scale: 重缩放因子,用于将历史累加值缩放到新的最大值基准
re_scale = tl.exp(e_max - n_e_max)
# p: 计算 softmax 概率,exp(qk - max)
p = tl.exp(qk - n_e_max[:, None])
# deno: 更新分母累加器,历史值重缩放后加上当前块的概率和
deno = deno * re_scale + tl.sum(p, 1)
# offs_buf_v: 计算 V_Buffer 的内存偏移
# - offs_kv_loc[:, None] * stride_buf_vbs: 根据物理位置索引计算 batch 维度偏移
# - cur_kv_head * stride_buf_vh: head 维度偏移
# - offs_d[None, :]: 特征维度偏移
offs_buf_v = (
offs_kv_loc[:, None] * stride_buf_vbs
+ cur_kv_head * stride_buf_vh
+ offs_d[None, :]
)
# v: 加载 V 矩阵的当前块,形状为 [BLOCK_N, BLOCK_DMODEL]
v = tl.load(V_Buffer + offs_buf_v, mask=mask_n[:, None], other=0.0)
# p = p.to(v.dtype): 将概率矩阵转换为 V 的数据类型(通常是 float16/bfloat16)
p = p.to(v.dtype)
# acc: 更新分子累加器,历史值重缩放后加上当前块的加权和 (p @ v)
acc = acc * re_scale[:, None] + tl.dot(p, v)
# e_max = n_e_max: 更新最大值为当前块的最大值
e_max = n_e_max
# ==================== Stage 2: 计算 extend 部分的因果注意力(三角形掩码)====================
# cur_block_m_end: 当前块的实际结束位置,防止超出序列长度
cur_block_m_end = tl.minimum(cur_seq_len_extend, (cur_block_m + 1) * BLOCK_M)
# 遍历 extend 部分的所有 KV 块(每次处理 BLOCK_N 个 token)
for start_n in range(0, cur_block_m_end, BLOCK_N):
# 确保 start_n 是 BLOCK_N 的倍数
start_n = tl.multiple_of(start_n, BLOCK_N)
# mask_n: extend 部分的有效位置掩码
mask_n = (start_n + offs_n) < cur_block_m_end
# load k in transposed way
# offs_k: 计算 K_Extend 的内存偏移(extend 部分是连续存储的)
offs_k = (
(cur_seq_extend_start_contiguous + start_n + offs_n[None, :]) * stride_kbs
+ cur_kv_head * stride_kh
+ offs_d[:, None]
)
# k: 加载 K_Extend 的当前块,形状为 [BLOCK_DMODEL, BLOCK_N]
k = tl.load(K_Extend + offs_k, mask=mask_n[None, :], other=0.0)
# qk: 初始化 QK 注意力分数矩阵
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
# qk += tl.dot(q, k): 计算 Q 和 K 的点积
qk += tl.dot(q, k)
# qk *= sm_scale: 应用缩放因子
qk *= sm_scale
# mask_causual: 因果掩码,确保每个位置只能看到之前的位置(三角形掩码)
# (cur_block_m * BLOCK_M + offs_m[:, None]) >= (start_n + offs_n[None, :])
# 表示当前 Q 的 token 位置必须 >= K 的 token 位置
mask_causual = (cur_block_m * BLOCK_M + offs_m[:, None]) >= (
start_n + offs_n[None, :]
)
# mask_causual &= mask_m[:, None] & mask_n[None, :]: 与有效位置掩码取交集
mask_causual &= mask_m[:, None] & mask_n[None, :]
# qk = tl.where(...): 应用因果掩码,将未来位置设为负无穷
qk = tl.where(mask_causual, qk, float("-inf"))
# ==================== Online Softmax 更新(与 Stage 1 相同)====================
# n_e_max: 更新后的最大值
n_e_max = tl.maximum(tl.max(qk, 1), e_max)
# re_scale: 重缩放因子
re_scale = tl.exp(e_max - n_e_max)
# p: 计算 softmax 概率
p = tl.exp(qk - n_e_max[:, None])
# deno: 更新分母累加器
deno = deno * re_scale + tl.sum(p, 1)
# offs_v: 计算 V_Extend 的内存偏移
offs_v = (
(cur_seq_extend_start_contiguous + start_n + offs_n[:, None]) * stride_vbs
+ cur_kv_head * stride_vh
+ offs_d[None, :]
)
# v: 加载 V_Extend 的当前块,形状为 [BLOCK_N, BLOCK_DMODEL]
v = tl.load(V_Extend + offs_v, mask=mask_n[:, None], other=0.0)
# p = p.to(v.dtype): 类型转换
p = p.to(v.dtype)
# acc: 更新分子累加器
acc = acc * re_scale[:, None] + tl.dot(p, v)
# e_max = n_e_max: 更新最大值
e_max = n_e_max
# ==================== 输出结果 ====================
# offs_o: 计算输出矩阵 O_Extend 的内存偏移
offs_o = (
(cur_seq_extend_start_contiguous + cur_block_m * BLOCK_M + offs_m[:, None])
* stride_obs
+ cur_head * stride_oh
+ offs_d[None, :]
)
# tl.store: 存储最终结果,acc / deno[:, None] 完成 softmax 归一化
tl.store(O_Extend + offs_o, acc / deno[:, None], mask=mask_m[:, None])在上面的代码中,几个关键参数和矩阵tiling思路:
- 注意拆分的grid,有三个维度
- 第一维是batchsize,也就是第几个请求
- 第二维是head头数,也就是第几个头,每8个头对应到一个相同的kv
- 第三维是tokens数,也就是200个tokens会被拆分成两个cdiv(200,128)
- BLOCK_M 是按照tokens个数来算的,也就是比如有200个token,那么会被拆成两次BLOCK_M
- BLOCK_DMODEL 是按照单个head的隐含层维度固定下来的,对于当前模型就是固定64
因此最后的q矩阵的维度是[BLOCK_M, BLOCK_DMODEL]
在计算部分,拆分成了两个部分,第一个是q和prefix的kv计算,第二个q和extend的kv计算, 拆成两个是因为两个部分的计算特性不一样,prefix在内存中是可能不连续的,而extend是连续(分配的时候就保证连续)
首先是q和prefix的kv进行计算: k的维度是:[BLOCK_DMODEL, BLOCK_N],这里的BLOCK_N是按照prefix的总的tokens数进行切分,只是上面的配置成BLOCK_M和BLOCK_N是一样的
onlinesoftmax:
acc是分子,每一步都在根据当前的最大值进行更新,累加是因为做了矩阵分块,所以是按照矩阵分块进行最终的矩阵乘加进行的累加。
deno是分母,这个值是不断更新的,在遍历完最后一个块完成更新,这个值本身是在softmax中,但是因为对于每个token对应的hidden state,只会有一个值,所以先进行了乘上v,最后再把分子除上了这个deno分母,也不影响最终的计算结果。
总之当前的online softmax好处是实时更新,永远不需要分配一个和矩阵size相同的临时激活值变量。在迭代完也就是完成了最终的计算
mask实现
在上面的代码中,分成了两个stage,一个是prefix一个是extend,两个stage实现的mask不同
- 对于第一个prefix,mask的作用只是为了范围分块超出索引边界,对于prefix的因果是全部都要计算的
- 对于第二个extend,mask就需要根据位置进行实际的掩码索引了,
1
2
3
4
5
6
mask_causual = (cur_block_m * BLOCK_M + offs_m[:, None]) >= (
start_n + offs_n[None, :]
)
mask_causual = (cur_block_m * BLOCK_M + offs_m[:, None]) >= (
start_n + offs_n[None, :]
)这段代码相比第一个prefix,多了第一句的q的位置需要大于等于k的位置









