qwen3-next线性注意力公式推导
qwen3-next线性注意力公式推导
gogongxt传统Attention Soft注意力计算复杂度(以双向注意力也就是忽略mask来着)
先来看注意力计算机制:
双向注意力的计算:
单向注意力的计算:
其中
为了方便展示,我们先忽略 softmax 符号和
1、先计算
2、先计算
先计算
先计算
在长序列场景下,
但是,由于softmax的限制,没办法进行交换运算,导致长序列场景下计算复杂度很高。
那么,能不能不使用softmax计算注意力呢?
对于双向注意力来说,由于没有
把
其中,
则
可见,如上形式可以看成是一个以
这样的好处是在长序列场景下,无需额外的显存来存储
不过,固定大小的状态矩阵是无法完美的存储所有历史信息的,每当新加入token的时俣,现有token就要被压缩,当序列长度变得很长的时候,每个token的信息占比很小,这就是为什么线性注意力检索能力比较差。
那么,一个很直观的想法是加入新token的时候遗忘掉一些不重要的历史信息(除旧迎新)。
可以给历史状态加入一个decay因子:
我们使用一个衰减矩阵(门控矩阵)来统一表述:
线性注意力的优化目标
状态矩阵
应用梯度下降进行优化:
所以
把
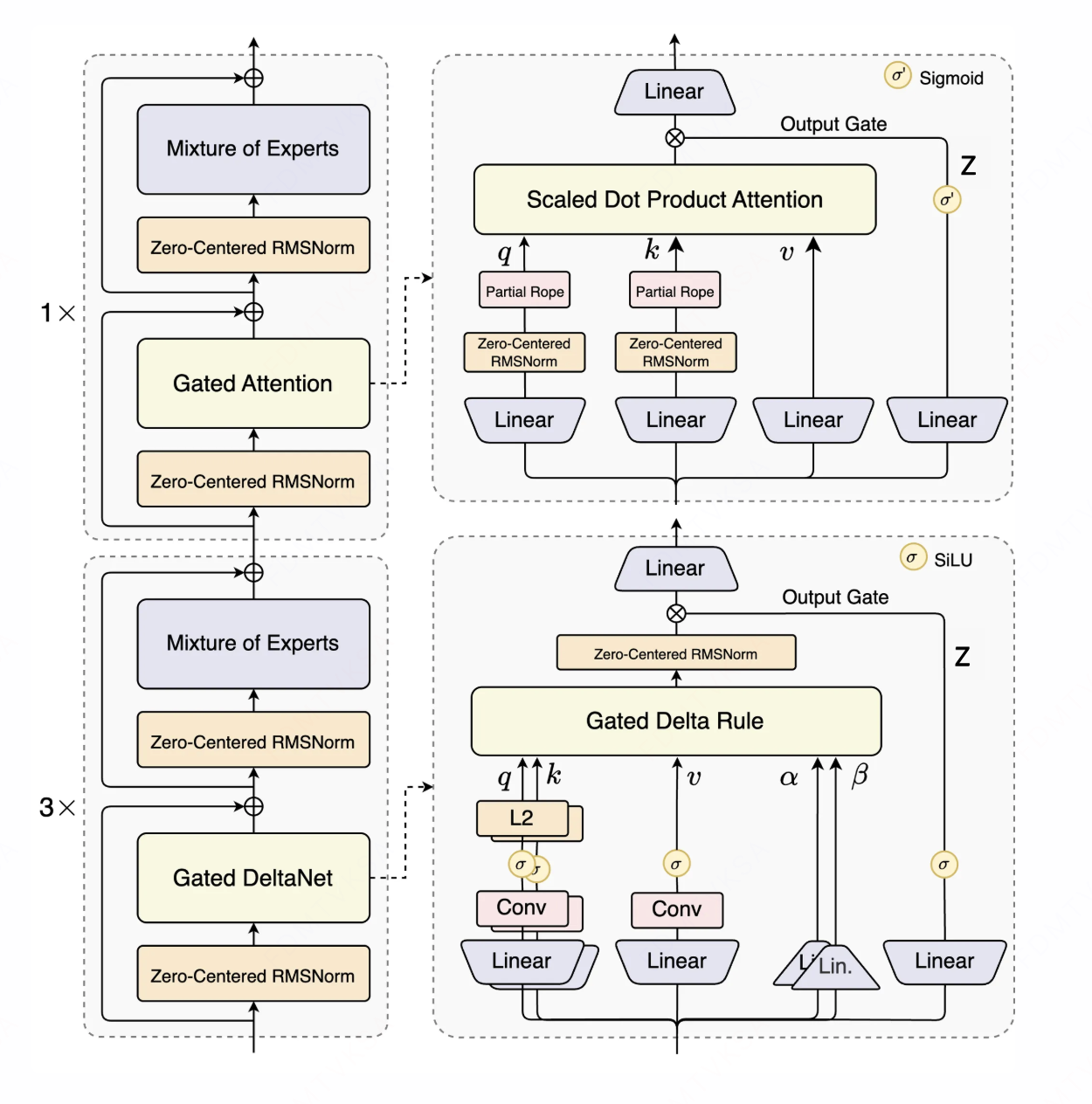
这就是Gated DeltaNet,也就是在qwen3-next模型中使用的线性注意力。
苏神的博客中说只
更加符合我们上面说的添加遗忘门的方式:
PS: 最初的线性Attention对应的损失函数为
即诙复了标准线性注意力更新。











