量化-01-综述

量化-01-综述
gogongxt最新博主在系统学习量化,之前都是以工程实践为主,缺少系统性的学习,最近找了一篇量化综述,学习了一下,收获颇丰
refer to: “A Comprehensive Evaluation on Quantization Techniques for Large Language Models” — arXiv:2507.17417
再结合工程经验,后面也会详细出AWQ,GPTQ,SmoothQuant等量化算法源码学习
量化基础
量化方法
每种量化方法都可以拆解为两步:
预量化变换——在量化前对数据进行预处理,使其更容易量化。这一步处理那些会主导量化范围的异常值。
量化误差缓解——在量化后补偿引入的误差。
SmoothQuant、AWQ、GPTQ、QuaRot、SpinQuant、FlatQuant 都是这两个基本模块的不同组合。
| Methods | Pre-quantization Transformation | Quantization Error Mitigation |
|---|---|---|
| SmoothQuant | Scaling | RTN |
| Outlier Suppression+ | Shifting + Scaling | RTN |
| GPTQ | - | GPTQ |
| ZeroQuant-v2 | - | Low-rank |
| QuIP | Rotation | GPTQ |
| AWQ | Scaling | RTN |
| Atom | Reorder | GPTQ |
| OmniQuant | Shifting + Scaling | GPTQ |
| Qserve | Scaling + Rotation | GPTQ |
| LQER | Scaling | Low-rank |
| QuaRot | Rotation | GPTQ |
| SpinQuant | Rotation | GPTQ |
| ResQ | Reorder + Rotation | GPTQ |
| FlatQuant | Scaling + Rotation | GPTQ |
| OSTQuant | Scaling + Rotation | GPTQ |
三种预量化变换方法:
Shifting(平移):消除激活分布在各通道间的不对称性。激活值分布往往是非对称的,且不对称程度因通道而异,通过平移让各通道中心对齐。
where the layer input
is shifting and becomes is a vector representing the channel-wise shifting parameters. To keep mathematical equivalence, an additional term, the product of and , is added to the bias . Scaling(缩放):将量化难度从激活转移到权重。激活中的异常值集中在某些通道,通过通道级缩放可以抑制这些异常值。
where
is a diagonal matrix composed of scaling factors of different channels, which can be obtained in various ways. As shown in Table IV, SmoothQuant [6] uses calibration to compute . AWQ [11], as a weight-only quantization, Rotation(旋转):将数据矩阵乘以正交矩阵,大幅改变激活分布,减少异常值。
where the input
is rotated with an orthogonal matrix , resulting in . To preserve the model’s output, the weight is simultaneously transformed by , which is the transpose of .
三种量化误差缓解方法:
RTN (Round-To-Nearest,就近取整):最简单的量化方式,直接舍入到最近的量化级别。
GPTQ:基于 Hessian 矩阵分析量化引入的损失误差,计算最优权重扰动来补偿误差。
where
is the loss function of the model evaluated at weights . and denote the quantized weights and their dequantized version, respectively. Self-compensation methods need to find an optimal weight perturbation to add to , such that the quantization loss error in Eq. (4) is minimized. Table VI summarizes the computation strategies of adopted by various self-compensation quantization methods. Low-rank(低秩补偿):引入低秩分支专门补偿量化误差,可以是 INT8 或保持 FP16。
where
, are low-rank matrices, and is the bottleneck rank. The product serves as a low-rank approximation of the quantization error. Table VII illustrates the computation process of the lowrank terms in some quantization methods.
量化粒度
Symmetry and granularity of quantization methods. For granularity, T: per-tensor, C: per-channel/token, G: per-group.
| Methods | Precision | Symmetric (W) | Symmetric (A) | Gran. |
|---|---|---|---|---|
| SmoothQuant | W8A8 | T | F | T, C |
| GPTQ | W3A16, W4A16 | T | - | G |
| ZeroQuant-v2 | W2/3/4A16, W4A8 | T, F | T, F | G |
| QuIP | W2/3/4A16 | T | - | G |
| AWQ | W3A16, W4A16 | T | - | G |
| Atom | W3A3, W4A4 | T | F | G |
| OmniQuant | W2/3/4A16, W4/6/8A4/6/8 | F | F | C |
| Qserve | W4A8 | T | F | C |
| LQER | W4A6, W4A8 | T | F | G |
| QuaRot | W4A4 | T | F | C, G |
| SpinQuant | W4A4, W4A8 | T | F | C |
| ResQ | W4A4 | T | F | C |
| FlatQuant | W4A4 | T | F | C |
| OSTQuant | W4A4 | T | F | C |
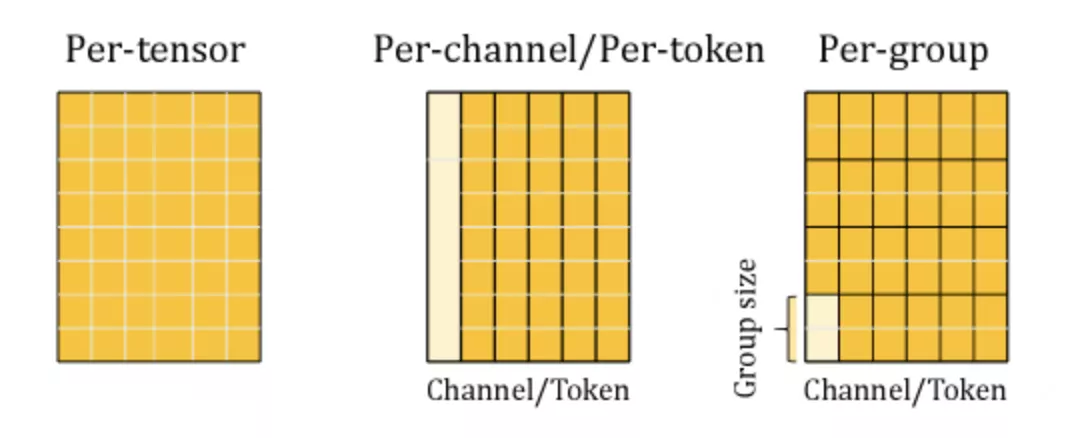
不同的量化粒度:
- per-tensor 也就是一整个张量矩阵只有一个参数
- per-channel 对权重矩阵,每一列一个参数
- per-group 在per-channel基础上再细分,把一列分成多个
- per-token 适用激活值,对token粒度,每一行一个参数
- block-wise 对权重,粒度不是按行/列划分,而是分成多个小块(例如 128×128),每个块有自己的缩放因子。比如 DeepSeek-V3 MoE 模型的 expert o_proj 矩阵(维度 2048×7168),量化参数就是(16x56)
- AWQ/GPTQ: W4A16,,权重用INT4(group-wise),激活值用FP16/BF16,也就是INT4权重加载进SRAM后会反量化为FP16/BF16和激活值做计算
- SmoothQuant: W8A8,权重用INT8(per-channel),激活值用INT8(per-token),实际调用的计算也是INT8的kernel
论文观点
预量化变换:什么真正有效
研究人员测试了三种方法:shifting(平移)、scaling(缩放)和 rotation(旋转)。
Rotation + Scaling 组合最强。 同时使用两个优化,效果最好。在 LLaMA-3.2-1B 上进行 W4A4 量化,这个组合配合 GPTQ 达到 11.8 的困惑度,而全精度模型是 9.76。
对称性和粒度设置
激活用非对称量化,权重用对称量化。
激活的分布天然是非对称的。强制对称量化会浪费资源。
权重的分布大致对称,非对称量化几乎没有帮助。
FP4:新前沿
NVIDIA 的 Blackwell 架构(RTX 50 系列)支持 FP4 格式:MXFP4 和 NVFP4。两者都使用 E2M1 编码(1 位符号、1 位尾数、2 位指数),但缩放策略不同。
NVFP4 胜过 MXFP4。 关键区别在于缩放因子。MXFP4 使用 E8M0(只能是 2 的幂次,如 1、2、4、8…),精度较低;NVFP4 使用两级缩放:per-tensor FP32 + per-group E4M3。E4M3 可以表示分数(如 1.5、2.5),但表示范围有限,所以需要 per-tensor FP32 先做大范围缩放。在 LLaMA-3.2-1B 上,NVFP4 配合 GPTQ + 低秩补偿达到 10.83 困惑度,而 MXFP4 是 12.69。
| 特性 | MXFP4 | NVFP4 |
|---|---|---|
| 组大小 | 32 | 16 |
| 缩放因子格式 | E8M0 | E4M3 + per-tensor FP32 |
| 缩放因子精度 | 只能是 2 的幂次(1, 2, 4, 8…) | 可表示分数(如 1.5, 2.5) |
为什么 NVFP4 更好:
更小的组大小(16 vs 32):粒度更细,每组独立缩放,更好地适应局部数据分布
更精确的缩放因子:
- E8M0 只有指数没有尾数,只能表示 2^n,精度粗糙
- E4M3 有 4 位指数 + 3 位尾数,可以表示分数
两级缩放策略:
- per-tensor FP32 先做大范围缩放(补偿 E4M3 表示范围有限的问题)
- per-group E4M3 做精细调整
rotation 对 FP4 帮助有限。 论文测试了 INT4 的最优策略(rotation + scaling + GPTQ)在 FP4 格式上的效果,提升很小。原因:FP4 极小的组大小(NVFP4 是 16,MXFP4 是 32)已经像 rotation 一样缓解了异常值,微块结构替你完成了这项工作。
旋转后 INT4 在 per-channel 设置下胜过 FP4。 没有预量化时,FP4 的非均匀分布比 INT4 更好地处理长尾数据。但旋转消除异常值后,INT4 的均匀分布反而成为优势。在 per-channel 量化加优化旋转的情况下,INT4 达到 11.8 困惑度,而 FP4 是 12.13。但在 per-group 设置下,FP4 仍然略好于 INT4。
缩放因子格式非常重要
论文测试了 4 位缩放因子(E2M1),结果简直是灾难——同时应用于权重和激活时,困惑度飙升到 4000 以上。
只应用于权重?性能还行,但仍不如 NVFP4 的 E4M3 缩放。
教训:不要在缩放因子精度上省。E4M3 格式加两级缩放方案(per-tensor FP32 + per-group E4M3)值得那些额外的比特。
核心结论
INT4 量化: 使用优化的 rotation + scaling + GPTQ,可选加低秩补偿进一步降低困惑度。
FP4 量化: 跳过 rotation——在小组大小时它是多余的。专注于缩放因子格式。
资源受限场景: 单用随机旋转比随机旋转 + 校准缩放更好。原因是旋转后校准方法不再准确——异常值在各通道间被平均化,无法简单基于最大值计算缩放参数。
非对称量化: 应用到激活,不是权重。激活分布天然非对称,权重分布大致对称。
缩放因子: E4M3 + per-tensor FP32(NVFP4 方案)胜过 E8M0(MXFP4 方案)。









