mamba-radix-cache-no-buffer

mamba-radix-cache-no-buffer
gogongxtSGLang
Mamba Radix Cache 深度解析:no_buffer 模式下的状态管理
no_buffer第一次引入来源于commit a55cf5304 #11214
在这个commit中贴出了对应的实现文档:
https://docs.google.com/document/d/1ZYBsZaz58NIIFmlOuQXqKPruIjv1ZJIUUrIj-sZlT4U/edit?tab=t.0
说明文档
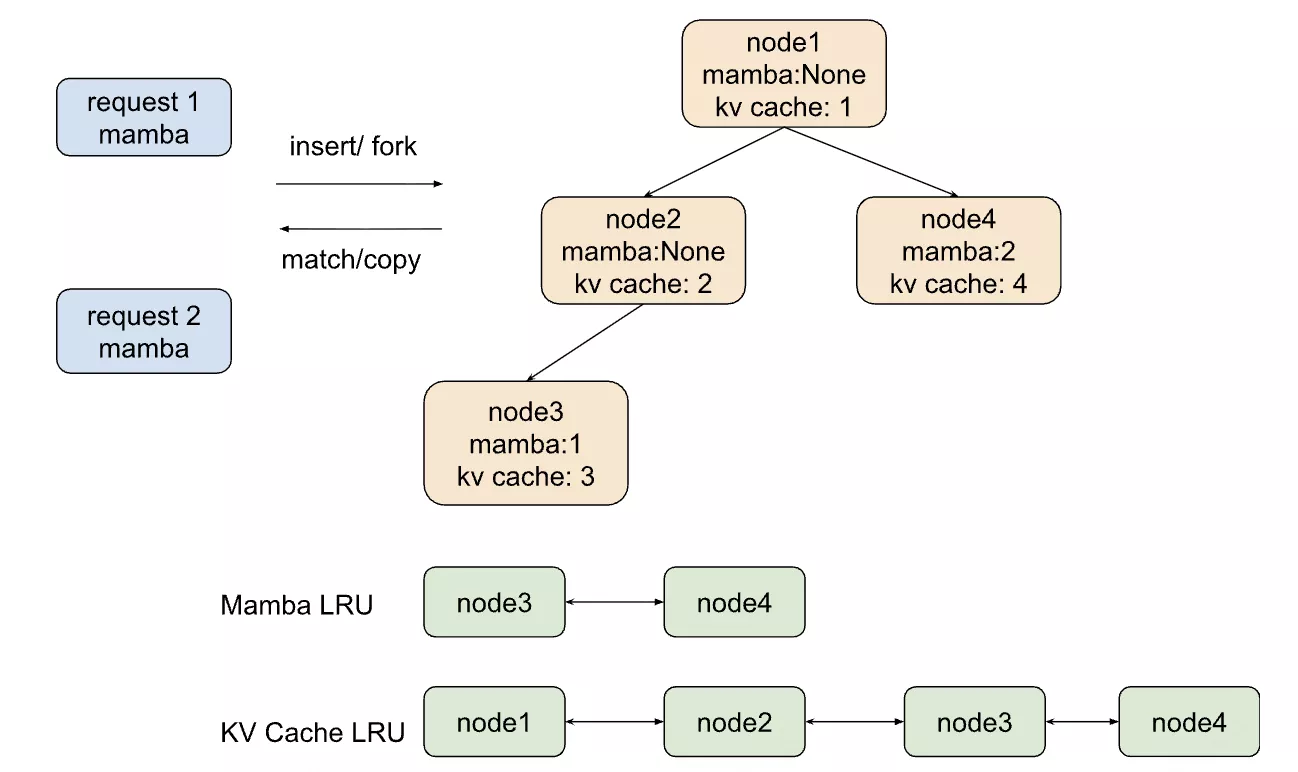
V0 uses LRU list for mamba cache/full attention for eviction like SWARadixCache. It currently only inserts request mamba cache into radix tree when do cache_finished_req / cache_unfinished_req. It can be modified to Marconi or k steps later
cache_finished_req / cache_unfinished_req:
- copy a request mamba state, and insert it into mamba radix tree (since mamba state is update in place)
- if mamba value has already existed, release this copied mamba value
insert:
- the same as radix tree, update full attention LRU value from the path.
- when split node, new_node should have be inserted into mamba LRU and full attention LRU
- when inserted place is a node with mamba tombstone, insert it into mamba LRU
- otherwise, mamba value has already existed.
- Tombstone:指 mamba_value=None 的节点(只有 KV cache,没有 mamba状态)
match:
- return the longest node from root node which both mamba value is not None
- reset full attention LRU from this node to root path
- reset mamba LRU only for selected node
- when a request needs matched node to do prefill, it needs copy this mamba state from tree to its mamba state.
evict:
- be used to evict full attention and evict mamba as well. only evict from leaves.
- remove leaf node from full attention and mamba LRU
- iteratively remove parent node until its mamba value is not None
evict_mamba:
- be used to evict mamba, can evict from any node
- for parent node, remove this node from LRU and release it from mamba pool
- for leaf node: the same as evict logic
inc_lock_ref:
- for full attention, lock from node to root
- for mamba, only lock itself if it has mamba value
dec_lock_ref:
- for full attention, unlock from node to root
- for mamba, only unlock itself if it has mamba value
背景
Qwen3-Next 等混合架构模型同时包含 Linear Attention (Mamba) 和 Softmax Attention。对于 Linear Attention 的前缀匹配,需要缓存 SSM 状态和 Conv 状态。
本文深入解析 no_buffer
模式下的缓存分配、索引、更新和生命周期管理机制。
完整流程图
短请求流程(长度 ≤ chunked_prefill_size)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
┌─────────────────────────────────────────────────────────────────────────┐
│ 短请求处理流程(无 chunk) │
└─────────────────────────────────────────────────────────────────────────┘
1. 请求到达
│
├─ alloc() → 分配 mamba_pool_idx (假设为 slot 5)
│ └─ MambaPool.alloc(1) → free_slots 取出索引,清零状态
│
▼
2. 前缀匹配 match_prefix()
│
├─ 遍历 Radix Tree,找到最长匹配节点
│ └─ 节点存储: mamba_value = slot_index (如 slot 3)
│
├─ COW: 复制匹配状态到请求空间
│ └─ copy_from(src=3, dst=5) # 复制 slot 3 → slot 5
│
▼
3. Forward 计算
│
├─ Conv: causal_conv1d_fn(update=True)
│ └─ conv_state[layer, 5] 被更新
│
├─ SSM: mamba_chunk_scan_combined()
│ └─ ssm_state[layer, 5] 被更新
│
▼
4. 请求完成 cache_finished_req()
│
├─ fork_from(5) → 分配新 slot (假设为 slot 8)
│ └─ copy_from(5 → 8) # 复制最终状态
│
├─ insert() → 将 slot 8 插入 Radix Tree
│ └─ TreeNode.mamba_value = tensor([8])
│
├─ free_mamba_cache(req) → 释放 slot 5
│ └─ free_slots.append(5)
│
▼
5. 后续请求匹配
│
└─ match_prefix() → 找到 slot 8 → COW 到新请求空间长请求流程(长度 > chunked_prefill_size)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
┌─────────────────────────────────────────────────────────────────────────┐
│ 长请求处理流程(Chunked Prefill) │
│ 请求长度 10k,chunk_size = 8192 │
└─────────────────────────────────────────────────────────────────────────┘
1. 请求到达
│
├─ alloc() → 分配 mamba_pool_idx = slot 5
│
▼
2. 前缀匹配 match_prefix()
│
└─ 假设找到 slot 3,COW: copy_from(3 → 5)
│
▼
3. Chunk 1: tokens[0:8192]
│
├─ Forward 计算,更新 slot 5 的状态
│
├─ cache_unfinished_req()
│ │
│ ├─ fork_from(5) → slot 8
│ ├─ insert(slot 8) → Radix Tree 在 8192 边界点
│ │ └─ TreeNode(key=[0:8192], mamba_value=tensor([8]))
│ │
│ └─ 不释放 slot 5!请求继续使用
│
▼
4. Chunk 2: tokens[8192:10000]
│
├─ 使用 slot 5 继续计算(状态从 chunk 1 结束处继续)
│
├─ Forward 计算,更新 slot 5 的状态
│
└─ cache_finished_req()
│
├─ fork_from(5) → slot 9
├─ insert(slot 9) → Radix Tree 完整序列
│ └─ TreeNode(key=[0:10000], mamba_value=tensor([9]))
│
└─ free_mamba_cache(req) → 释放 slot 5
│
▼
5. Radix Tree 最终状态
│
├─ 节点 [0:8192]: mamba_value = slot 8 (chunk 边界)
└─ 节点 [0:10000]: mamba_value = slot 9 (完整序列)关键点:Chunk 边界的中间状态(slot 8)允许后续请求在 chunk 边界处进行前缀匹配,即使原始请求尚未完全结束。
核心数据结构
1. MambaPool:状态存储的核心
Mamba 状态存储在 MambaPool
中(memory_pool.py:188-386),包含两种状态:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class MambaPool:
def __init__(self, ...):
# Conv State: 每层一个 tensor
# qwen3-next是分别对qkv做卷积,这里把他们打包在conv_dim一起存储了,所以没有体现出来
# 形状: [num_mamba_layers, size+1, conv_dim/tp, conv_kernel-1]
conv_state = [
torch.zeros(
size=(num_mamba_layers, size + 1) + conv_shape,
dtype=conv_dtype, # 默认 bfloat16
device=device,
)
for conv_shape in conv_state_shape # 通常是 [(conv_dim/tp, conv_kernel-1)]
]
# SSM State (Temporal State): 单个 tensor
# 形状: [num_mamba_layers, size+1, num_heads/tp, head_dim, state_size]
temporal_state = torch.zeros(
size=(num_mamba_layers, size + 1) + temporal_state_shape,
dtype=ssm_dtype, # 默认 float32
device=device,
)1
2
3
4
5
6
7
8
9
10
11
┌─────────────────────────────────────────────────────────────────────────┐
│ MambaPool │
├─────────────────────────────────────────────────────────────────────────┤
│ conv_state[i]: [num_layers, size+1, conv_dim/tp, conv_kernel-1] │
│ ↓ Conv 状态,每层独立,存储卷积核的历史输入 │
│ │
│ temporal_state: [num_layers, size+1, num_heads/tp, head_dim, dstate] │
│ ↓ SSM 状态,每层独立,存储隐状态 h │
│ │
│ free_slots: 可用的 slot 索引列表 │
└─────────────────────────────────────────────────────────────────────────┘以 Qwen3-Next 为例:
conv_state_shape = [(conv_dim/tp, 3)]— 卷积核大小通常为 4,历史长度为 3temporal_state_shape = (num_heads/tp, 128, 128)— 32 头,head_dim=128,state_size=128
2. 索引管理:请求到状态的映射
1
2
3
4
HybridReqToTokenPool
├── req_to_token: [size, max_context_len] → KV cache indices
├── req_index_to_mamba_index_mapping: [size] → MambaPool slot indices
└── mamba_pool: MambaPool 实例每个请求通过 req.mamba_pool_idx 持有一个 Mamba slot
index,用于访问该请求的 Conv 和 SSM 状态。
3. Radix Tree 节点结构
1
2
3
4
class TreeNode:
key: RadixKey # token 序列
value: torch.Tensor # KV cache indices (每个 token 对应的索引)
mamba_value: torch.Tensor # Mamba slot index (单个索引,指向 MambaPool)mamba_value 是一个 单索引,因为 Mamba
状态是序列级别的,不像 KV cache 是 token 级别的。
缓存分配流程
请求初始化
当新请求到达时,HybridReqToTokenPool.alloc() 分配 Mamba
slot:
1
2
3
4
5
6
7
8
9
10
11
12
def alloc(self, reqs: List["Req"]):
for req in reqs:
if req.mamba_pool_idx is not None:
# 已有索引(来自 radix cache 前缀匹配)
mid = req.mamba_pool_idx
else:
# 分配新 slot
mid = self.mamba_pool.alloc(1)
req.mamba_pool_idx = mid[0]
# 建立映射
self.req_index_to_mamba_index_mapping[select_index] = mamba_indicesMambaPool.alloc() 的实现:
1
2
3
4
5
6
7
8
9
10
def alloc(self, need_size: int):
select_index = self.free_slots[:need_size]
self.free_slots = self.free_slots[need_size:]
# 分配时清零,避免脏数据
for conv_tensor in self.mamba_cache.conv:
conv_tensor[:, select_index] = 0
self.mamba_cache.temporal[:, select_index] = 0
return select_indexForward 中的状态更新
在 MambaMixer2.forward()
中,状态通过索引被访问和更新:
Prefill 阶段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 获取状态索引
state_indices_tensor = metadata.mamba_cache_indices # [num_reqs]
conv_state = layer_cache.conv[0]
ssm_state = layer_cache.temporal
# Conv 计算,同时更新 conv_state
hidden_states_B_C = causal_conv1d_fn(
x, conv_weights, bias,
conv_states=conv_state, # 被更新
cache_indices=state_indices_tensor, # 每个请求的 slot index
query_start_loc=query_start_loc,
)
# SSM 计算,返回 final state
varlen_state = mamba_chunk_scan_combined(
hidden_states, dt, A, B, C, ...
initial_states=initial_states, # 来自前缀匹配
return_varlen_states=True,
)
# 更新 ssm_state
ssm_state[state_indices_tensor] = varlen_stateDecode 阶段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# Conv 增量更新(单 token)
hidden_states_B_C = causal_conv1d_update(
hidden_states_B_C,
conv_state, # in-place 更新
conv_weights, bias,
conv_state_indices=state_indices_tensor,
)
# SSM 增量更新(单 token)
selective_state_update(
ssm_state, # in-place 更新
hidden_states, dt, A, B, C, D,
state_batch_indices=state_indices_tensor,
out=output,
)Radix Tree 缓存管理
前缀匹配
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
def _match_prefix_helper(self, key: RadixKey):
while len(key) > 0 and child_key in node.children.keys():
child = node.children[child_key]
# 如果当前节点有 mamba_value,更新最佳匹配
if node.mamba_value is not None:
best_value_len = len(value)
best_last_node = node
# 处理 split 情况(部分匹配)
if prefix_len < len(child.key):
new_node = self._split_node(child.key, child, prefix_len)
if child.mamba_value is not None:
best_value_len = len(value)
best_last_node = child
break
value.append(child.value)
node = child匹配后状态复制(Copy-On-Write)
1
2
3
4
5
6
7
8
if cow_mamba and last_node.mamba_value is not None:
if req.mamba_pool_idx is None:
dst_index = self.mamba_pool.alloc(1)
else:
dst_index = req.mamba_pool_idx.unsqueeze(0)
src_index = last_node.mamba_value # radix tree 中的 slot
self.mamba_pool.copy_from(src_index, dst_index) # 复制状态请求完成后缓存(cache_finished_req)
关键问题:为什么需要 fork_from
而不是直接转移所有权?
1
2
3
4
5
6
7
8
9
10
def cache_finished_req(self, req: Req, is_insert: bool = True):
# Fork: 分配新 slot 并复制状态
mamba_value = req.mamba_pool_idx.unsqueeze(-1).clone()
mamba_value_forked = self.mamba_pool.fork_from(mamba_value)
# 插入 radix tree
result = self.insert(..., mamba_value=mamba_value_forked)
# 释放请求的原始 slot
self.req_to_token_pool.free_mamba_cache(req)Chunk 中间缓存(cache_unfinished_req)
当请求长度超过 chunked_prefill_size(默认
8192)时,请求会被分成多个 chunk 处理。每个 chunk 完成后,会调用
cache_unfinished_req 将当前状态缓存到 Radix Tree。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
def cache_unfinished_req(self, req: Req, chunked=False):
token_ids = req.fill_ids
cache_len = len(token_ids) # no_buffer 模式下缓存整个 chunk
# 获取当前请求的 mamba slot index
mamba_value = self.req_to_token_pool.get_mamba_indices(
req.req_pool_idx
).unsqueeze(-1)
# Fork 到新 slot(与 cache_finished_req 相同)
mamba_value_forked = self.mamba_pool.fork_from(mamba_value)
# 插入 radix tree
result = self.insert(
InsertParams(
key=RadixKey(page_aligned_token_ids, req.extra_key),
value=page_aligned_kv_indices,
mamba_value=mamba_value_forked,
)
)
# 关键区别:不释放原始 mamba slot!
# 请求还在进行中,需要继续使用
# 更新请求的 last_node 用于后续 chunk
req.last_node = new_last_nodecache_unfinished_req 与
cache_finished_req 的关键区别:
| 操作 | cache_unfinished_req |
cache_finished_req |
|---|---|---|
| Fork 状态 | ✓ | ✓ |
| 插入 Radix Tree | ✓ | ✓ |
| 释放原始 slot | ✗(请求继续) | ✓(请求结束) |
更新 req.last_node |
✓(后续 chunk 使用) | ✗ |
为什么 Chunk 模式下需要
cache_unfinished_req?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
请求长度 10k > chunked_prefill_size (8192)
Chunk 1: tokens[0:8192]
│
├─ Forward 计算,更新 slot 5 的状态
│
└─ cache_unfinished_req()
├─ fork_from(5) → slot 8
├─ insert(slot 8) → Radix Tree 在 8192 边界点有状态
└─ 不释放 slot 5,请求继续
Chunk 2: tokens[8192:10000]
│
├─ 使用 slot 5 继续计算(从 chunk 1 的最终状态开始)
│
└─ cache_finished_req()
├─ fork_from(5) → slot 9
├─ insert(slot 9) → Radix Tree 在完整序列有状态
└─ 释放 slot 5这样设计的好处是:后续请求如果前缀在 chunk 边界(如 8192),可以直接匹配到 Radix Tree 中的状态,而不需要等待原始请求完全结束。
关键数据维度总结
| 组件 | 形状 | 说明 |
|---|---|---|
MambaPool.conv[i] |
[L, size+1, conv_dim/tp, K-1] |
Conv 状态,每层独立 |
MambaPool.temporal |
[L, size+1, H/tp, head_dim, dstate] |
SSM 状态,每层独立 |
req.mamba_pool_idx |
标量 int | 请求的 mamba slot index |
TreeNode.mamba_value |
[1] tensor |
Radix Tree 节点的 slot index |
state_indices_tensor |
[num_reqs] |
批量状态索引(用于 forward) |
总结
SGLang 的 Mamba 缓存机制通过以下设计实现了高效的状态管理:
- Pool + Index 架构:集中存储状态,通过索引间接访问,支持高效的状态复制和转移
- Radix Tree 前缀匹配:利用 token 序列的公共前缀,减少重复计算
- Copy-On-Write:前缀匹配时复制状态,保证不同请求的状态独立
- Fork 机制:请求完成时 fork 状态到新 slot,确保 Radix Tree 拥有独立副本,生命周期独立管理
这套机制在 no_buffer 模式下尤为关键,因为没有额外的
ping-pong buffer 来追踪状态变化,必须正确管理每个 slot
的所有权和生命周期。
当前存在的bug
注意,当前的代码实现,nobuffer是有bug的,对于请求长度小于chunked prefill,并不能正确缓存下来 假如chunk size是8k,第一次输入1k数据,完成后再次请求相同请求,cached_tokens是0 而如果请求是9k,第二次时cached_tokens是8k,也就是会在chunked prefill的边界缓存下来 细节来说就是cache_finished_req有bug,而cache_unfinished_req是正确的
另外还有一个问题:no_buffer模式没有处理FLA的64位对齐要求,即使修复了上述bug, 缓存的SSM状态位置可能不是64的倍数,导致状态恢复时可能出错。
然后对于decode来说,在nobuffer下并没有实现缓存前缀,在extra-buffer实现了decode间隔缓存
测试环境
启动服务:
1
2
3
4
python3 -m sglang.launch_server --host 0.0.0.0 --port 8055 \
--model-path /path/to/Qwen3-Next-80B-A3B-Instruct-4layers \
--mamba-scheduler-strategy no_buffer \
--enable-metrics --enable-cache-report现象描述
串行发送两条相同的请求:
| 请求长度 | 第一次请求 cached_tokens | 第二次请求 cached_tokens |
|---|---|---|
| 1k | 0 | 0 (期望有命中) |
| 9k | 0 | 8192 (chunked_prefill_size) |
关键观察:
- 请求长度 <
chunked_prefill_size(默认 8192):没有前缀匹配 - 请求长度 >
chunked_prefill_size:可以匹配到 chunked_prefill_size 边界
Bug 根因分析
问题一:cache_finished_req
没有正确复制 Mamba 状态
源码位置:
python/sglang/srt/mem_cache/mamba_radix_cache.py
原始代码 (cache_finished_req 第 549-560
行):
1
2
3
4
5
6
7
8
9
10
11
else:
mamba_value = req.mamba_pool_idx.unsqueeze(-1).clone()
mamba_ping_pong_track_buffer_to_keep = None
result = self.insert(
InsertParams(
key=RadixKey(token_ids[:page_aligned_len], req.extra_key),
value=page_aligned_kv_indices,
mamba_value=mamba_value,
)
)问题分析:
- 只复制了
mamba_pool_idx的值(tensor),没有复制实际的 mamba 状态数据 - 插入 radix tree 后,
free_mamba_cache会释放原始的 mamba slot - Radix tree 中存储的 index 指向已被释放的 slot,数据无效
对比 cache_unfinished_req (chunked
prefill 场景):
cache_unfinished_req 正确使用了 fork_from
来复制 mamba 状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
else:
mamba_value = self.req_to_token_pool.get_mamba_indices(
req.req_pool_idx
).unsqueeze(-1)
# 关键:fork_from 会复制状态到新 slot
mamba_value_forked = self.req_to_token_pool.mamba_pool.fork_from(mamba_value)
result = self.insert(
InsertParams(
key=RadixKey(page_aligned_token_ids, req.extra_key),
value=page_aligned_kv_indices,
mamba_value=mamba_value_forked, # 新 slot 的 index
)
)问题二:_match_prefix_helper
在 split 后丢失 mamba 状态引用
源码位置:
python/sglang/srt/mem_cache/mamba_radix_cache.py 第 953-993
行
场景分析:
当第二个请求匹配时,假设请求长度为 1007(减1用于 logprob),而 radix tree 中节点 key 长度为 1008:
1
2
3
4
5
6
7
8
9
10
11
12
13
while len(key) > 0 and child_key in node.children.keys():
child = node.children[child_key]
# 更新 best_value_len
if node.mamba_value is not None:
best_value_len = len(value)
best_last_node = node
prefix_len = self.key_match_fn(child.key, key)
if prefix_len < len(child.key): # 1007 < 1008,触发 split
new_node = self._split_node(child.key, child, prefix_len)
value.append(new_node.value)
node = new_node
break # 循环结束,但没有更新 best_value_len!问题分析:
prefix_len=1007 < child.key_len=1008,触发_split_node_split_node创建新节点作为父节点,mamba_value=None- 原 child 变为新节点的子节点,保留
mamba_value=5 - 循环 break,但
best_value_len没有被更新 - 最终返回
best_value_len=0,匹配失败
调试日志验证:
1
2
[DEBUG] _match_prefix_helper: matched child 7, prefix_len=1007, child.key_len=1008
[DEBUG] _match_prefix_helper: result value_len=1, best_value_len=0, best_last_node=0问题三:no_buffer
模式未处理 FLA 64 位对齐要求
背景:FLA (Flash Linear Attention) 库要求 SSM 状态以 64 (FLA_CHUNK_SIZE) 为倍数进行缓存。
源码位置:
python/sglang/srt/layers/attention/fla/chunk_delta_h.py:19
1
CHUNK_SIZE = 64问题分析:
在 cache_finished_req 中,no_buffer
模式直接使用完整长度缓存,没有做 FLA 对齐:
1
2
3
4
5
6
# cache_finished_req 第 508-512 行
cache_len = (
req.mamba_last_track_seqlen # ✅ extra_buffer: 对齐后的长度
if self.enable_mamba_extra_buffer
else len(token_ids) # ❌ no_buffer: 完整长度,未对齐!
)extra_buffer 模式的正确处理:
1
2
3
4
5
6
7
8
9
# schedule_batch.py - extra_buffer 模式的对齐计算
mamba_cache_chunk_size = get_global_server_args().mamba_cache_chunk_size # 通常是 64
mamba_track_seqlen_aligned = (
len(req.prefix_indices)
+ (req.extend_input_len // mamba_cache_chunk_size)
* mamba_cache_chunk_size # 向下对齐到 64 的倍数
)
req.mamba_last_track_seqlen = mamba_track_seqlen_aligned问题场景:
1
2
3
4
5
6
7
8
9
10
请求长度 = 100 (不是 64 的倍数)
extra_buffer 模式:
cache_len = (100 // 64) * 64 = 64 (向下对齐)
SSM 状态在位置 64 处正确缓存 ✅
no_buffer 模式:
cache_len = 100 (未对齐)
SSM 状态在位置 100 处缓存 ❌
但 FLA 的 SSM 状态只在 64 的倍数位置是有效的!为什么这是个问题?
根据 hybrid_linear_attn_backend.py 的注释:
1
2
3
4
5
# There are 3 cases for mamba_track_seqlen:
# 1) aligned with FLA_CHUNK_SIZE -> retrieve from last_recurrent_state
# a) is the last position -> retrieve from last_recurrent_state
# b) is NOT the last position -> retrieve from h
# 2) unaligned with FLA_CHUNK_SIZE -> retrieve from h如果缓存的 SSM 状态位置不是 64 的倍数,在恢复时可能无法正确获取状态,导致计算结果错误。
修复方案:
1
2
3
4
5
6
7
8
9
# cache_finished_req 修复
mamba_cache_chunk_size = get_global_server_args().mamba_cache_chunk_size
# no_buffer 模式也需要做 FLA 对齐
cache_len = (
req.mamba_last_track_seqlen
if self.enable_mamba_extra_buffer
else (len(token_ids) // mamba_cache_chunk_size) * mamba_cache_chunk_size # 向下对齐
)Bug 总结
| 问题 | 原因 | 修复 |
|---|---|---|
| 问题一 | cache_finished_req 没有复制 mamba 状态 |
使用 fork_from 复制状态到新 slot |
| 问题二 | _match_prefix_helper split 后丢失 mamba 引用 |
检查 child 的 mamba_value 并更新
best_value_len |
| 问题三 | no_buffer 模式未处理 FLA 64 位对齐 |
缓存长度向下对齐到 mamba_cache_chunk_size 的倍数 |
这三个问题共同导致了 no_buffer
模式下短请求无法正确进行前缀匹配。









