投机采样

投机采样
gogongxt论文:
- 在sglang 0.5.9版本中,实现了MTP/NEXTN,EAGLE,EAGLE3,单独draft小模型,NGRAM 的投机采样算法
- 其中MTP和NEXTN其实也是基于eagle的增加一些if,else修改实现的
- 没有实现Medusa
| Algorithm | Enum Value | Description |
|---|---|---|
| EAGLE | EAGLE |
Original EAGLE (Eagle 1) - draft model based speculative decoding |
| EAGLE3 | EAGLE3 |
EAGLE version 3 with auxiliary hidden states support |
| STANDALONE | STANDALONE |
Standalone draft model without target model weight sharing |
| NGRAM | NGRAM |
N-gram based speculative decoding (no neural draft model) |
| NONE | NONE |
No speculative decoding (default) |
Medusa
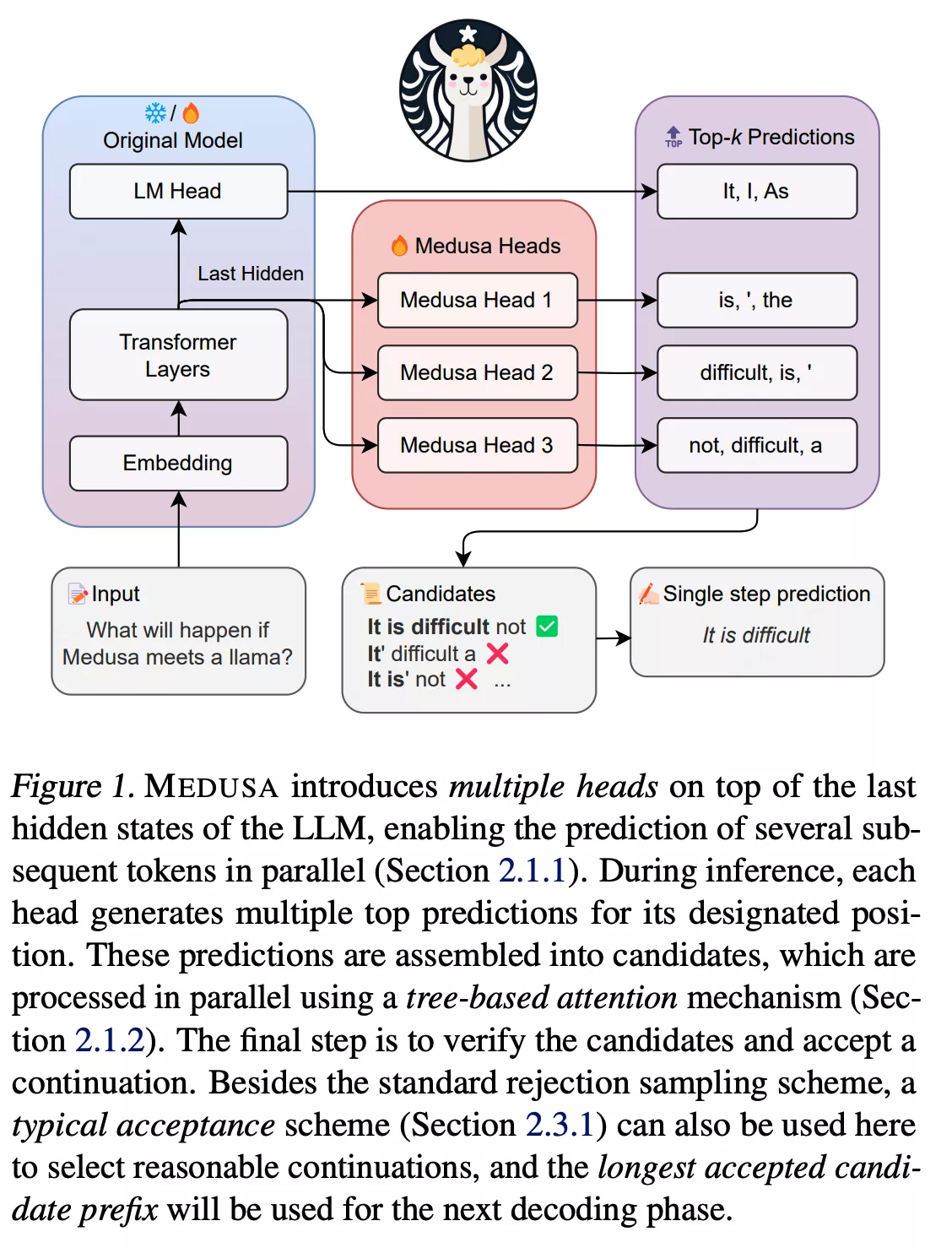
对Medusa架构来说,是在原有的LM Head单头基础上,增加几个头,预测后面的token
什么是 Medusa 的“多头”?
在传统的 LLM 中,网络的最顶端只有一个 LM
Head(语言模型头)。它的任务很单一:接收最后一层的隐含层特征
Medusa 的“多头” (Multiple Heads)
,就是在这个主干网络的最后一层
- Original LM Head:负责预测第
个 Token。 - Medusa Head 1:直接预测第
个 Token。 - Medusa Head 2:直接预测第
个 Token。 - 以此类推。
Medusa 头的架构是什么样的?
Medusa 的头设计得非常轻量,目的是不增加太多的额外计算开销。它的架构通常是一个简单的残差块(ResBlock)。
假设 Target 模型的最后一层隐含层输出是
特征变换(ResBlock):将
通过一个带激活函数的单层线性映射,并加上残差连接: (其中
是这个头专属的权重矩阵,尺寸通常也是 ) 复用 LM Head 权重:拿到变换后的特征
后,Medusa 不会自己去乘以一个庞大的词表矩阵,而是直接复用 Target 模型自带的原始 LM Head 的权重矩阵 来输出概率分布:
本质上,每个 Medusa Head 就是一个单层的
MLP,它们都在努力学习一种“跳跃式”的映射关系:仅仅凭借
EAGLE (Extrapolation Algorithm for Greater Language-model Efficiency)
架构图

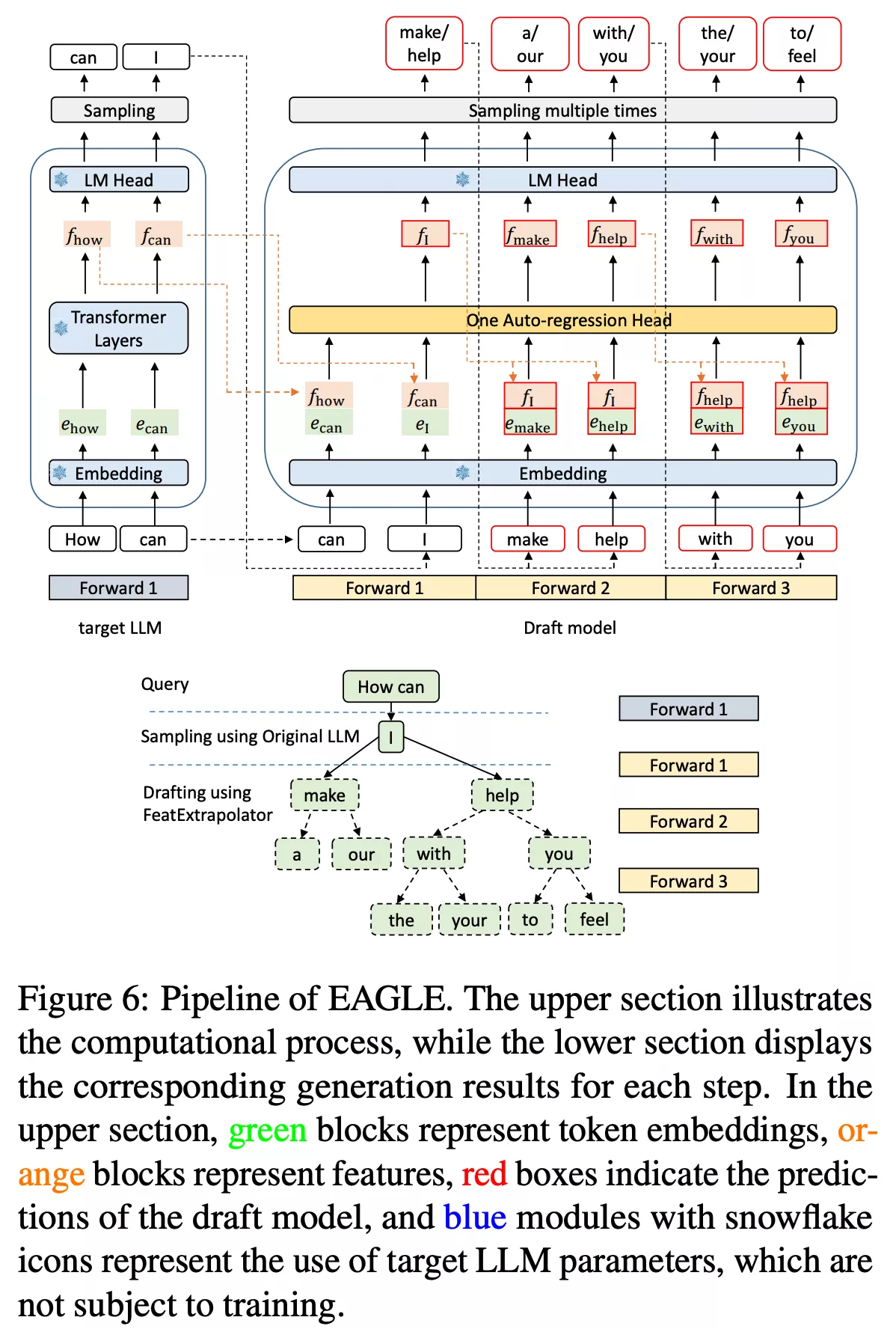
实现理解
EAGLE 的直觉是: Target 模型的
复用 Target 模型的高维特征,将其与 Token Embedding 结合,交给一个轻量级的 Draft 模型进行“特征外推”(Feature Extrapolation)。
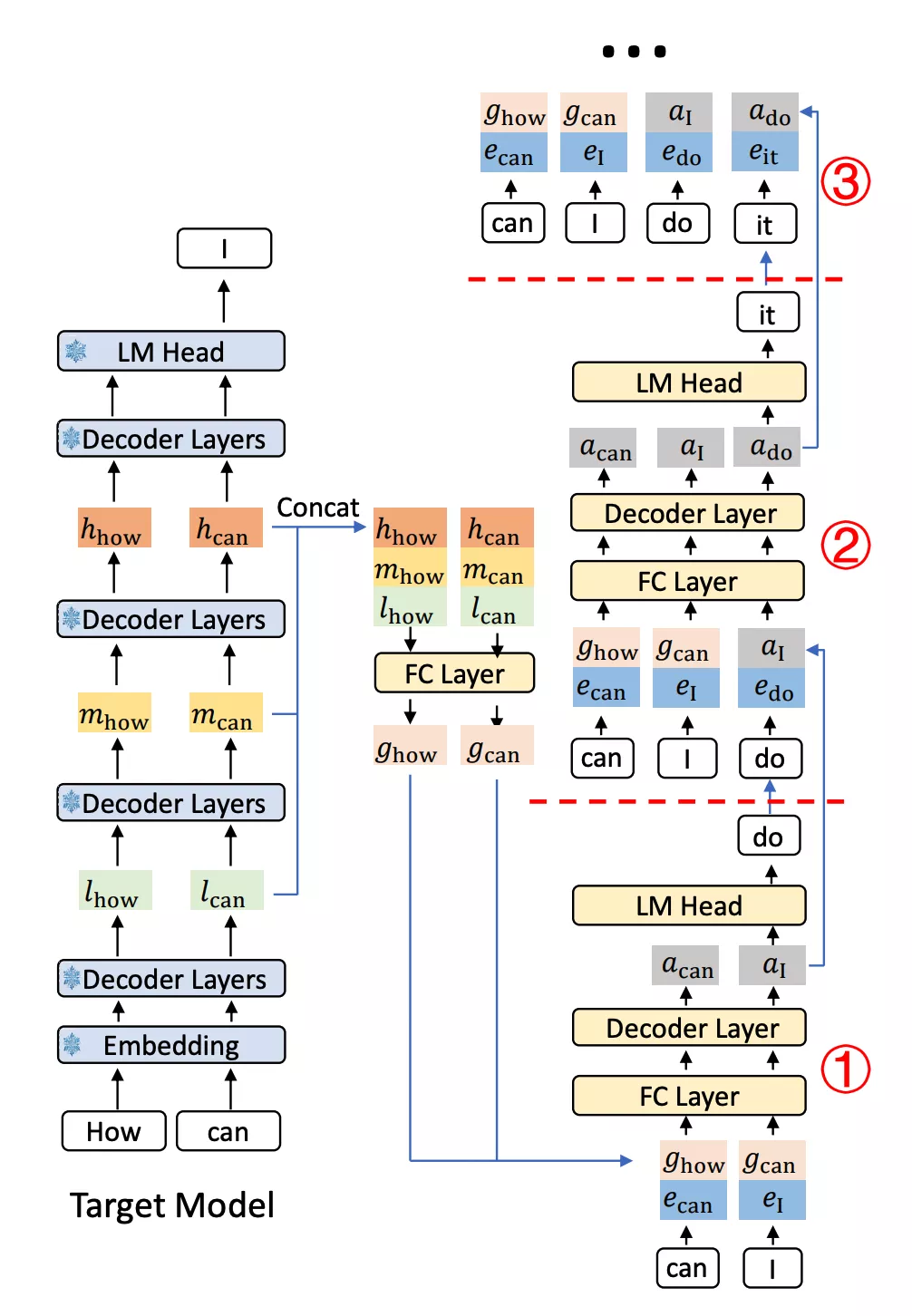
上面的架构图把流程讲的很清楚,这里简单梳理一下
Eagle模块输入是 上一层的深层语义特征
通过Embedding得到特征,假设维度是 - 得到的特征和
做concat,注意是最后一维做concat,得到维度 - 继续做一个fc层,就是
转成 - 把融合后的特征输入给One Auto-regression Head,本质上就是一个新的Transformer层
- 把输出给到和target model相同的LM Head,做采样后得到的就是预测的token
- 依次后推,就能继续得到后续的
token
注意几点:
- embedding和lm
head都是复用主模型的参数,
draft model的输出不是概率分布,而是预测特征 draft model也是一个transformer,所以也有kvcache,这里的计算和普通的attention是一样的,就当成模型多了一层,只是输入的特征是有操作的,另外MTP是和主模型同构的,而EAGLE没这个要求- 在prefill的时候,需要把所有的token做concat和fc,然后给到draft model做计算,这里会把kvcache存储下来
- decode就比较简单,就一个预测的token,和之前的kvcache做计算,没啥特殊的
MTP
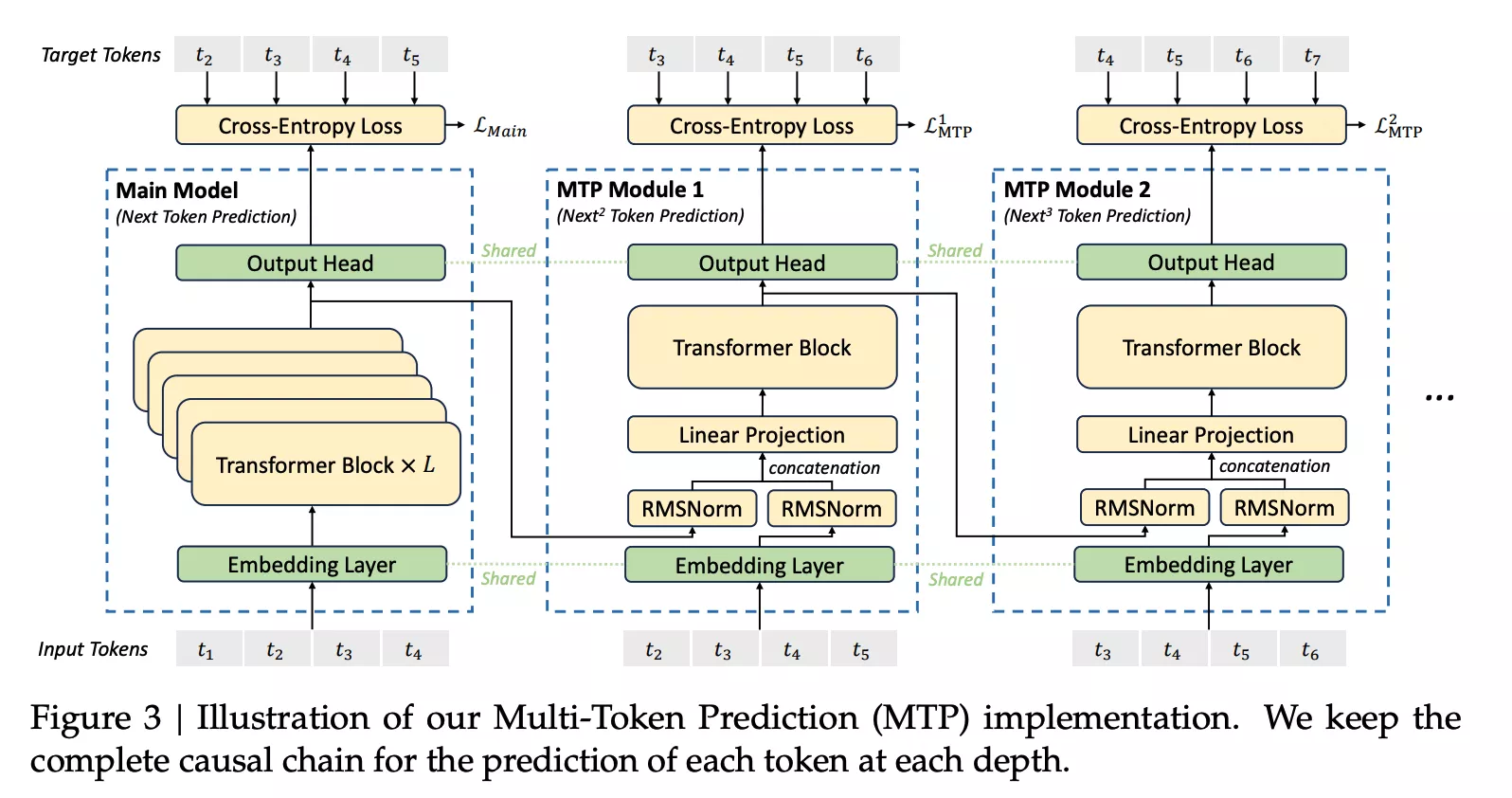
看懂了EAGLE,MTP就很好懂了,别的地方和EAGLE都一样,只是Transformer Block的输入,要对两个输入张量做rmsnorm,而EAGLE是直接concat
EAGLE2
EAGLE2 没有做什么结构上的变化,主要是在生成tokens树的过程中增加了剪枝的功能,可减少一些不必要的draft和verify数量,达到了加速效果
draft阈值判断

在EAGLE1中,我们构建draft树时固定指定TopK,在EAGLE2中通过阈值动态判断,低于阈值直接不要,不再固定
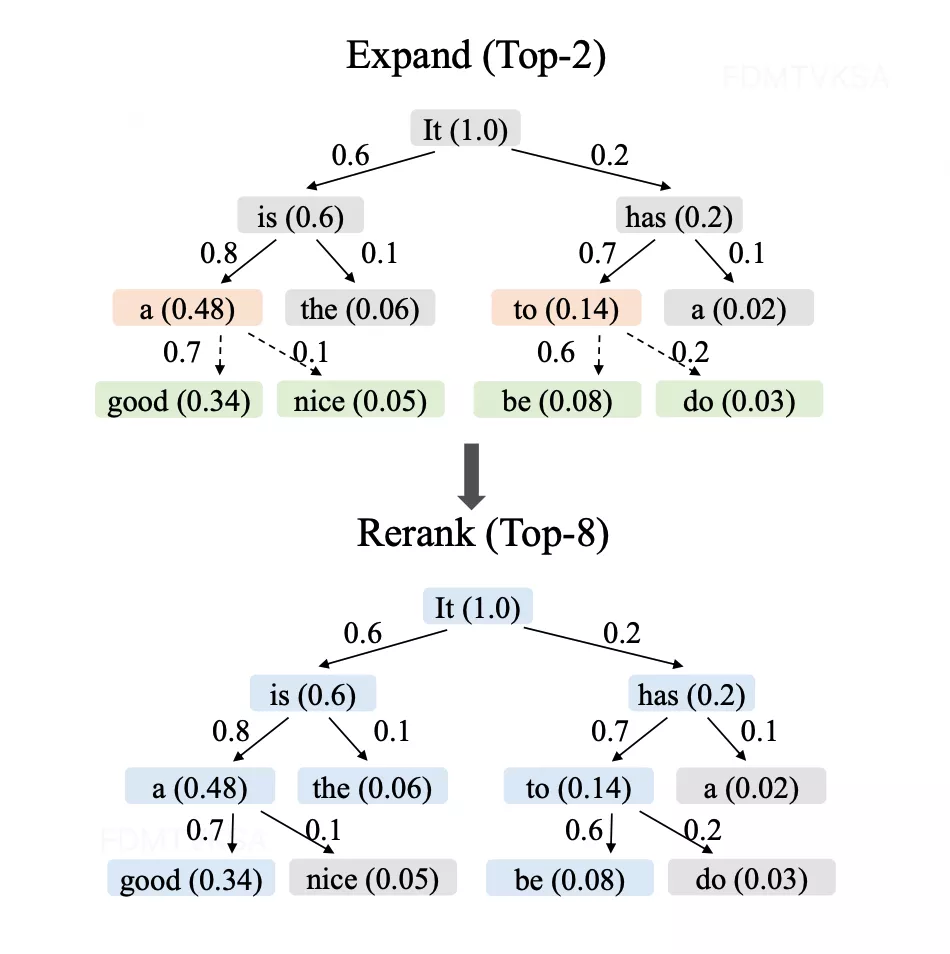
剪枝树的裁切
下面这张图展示了对树的操作,分成了两个阶段:
- Expand阶段,假设固定Top-2,即每一行都是挑概率最高的两个token draft后面的token,所以树的增长是2的幂次
- Rerank阶段,假设选择Top-8个token,每个token的概率是按照树从根节点开始累乘的,收集所有节点做排序选出最高的Top-8个token
Rerank就是EAGLE2的优化,根据token的级联概率做剪枝
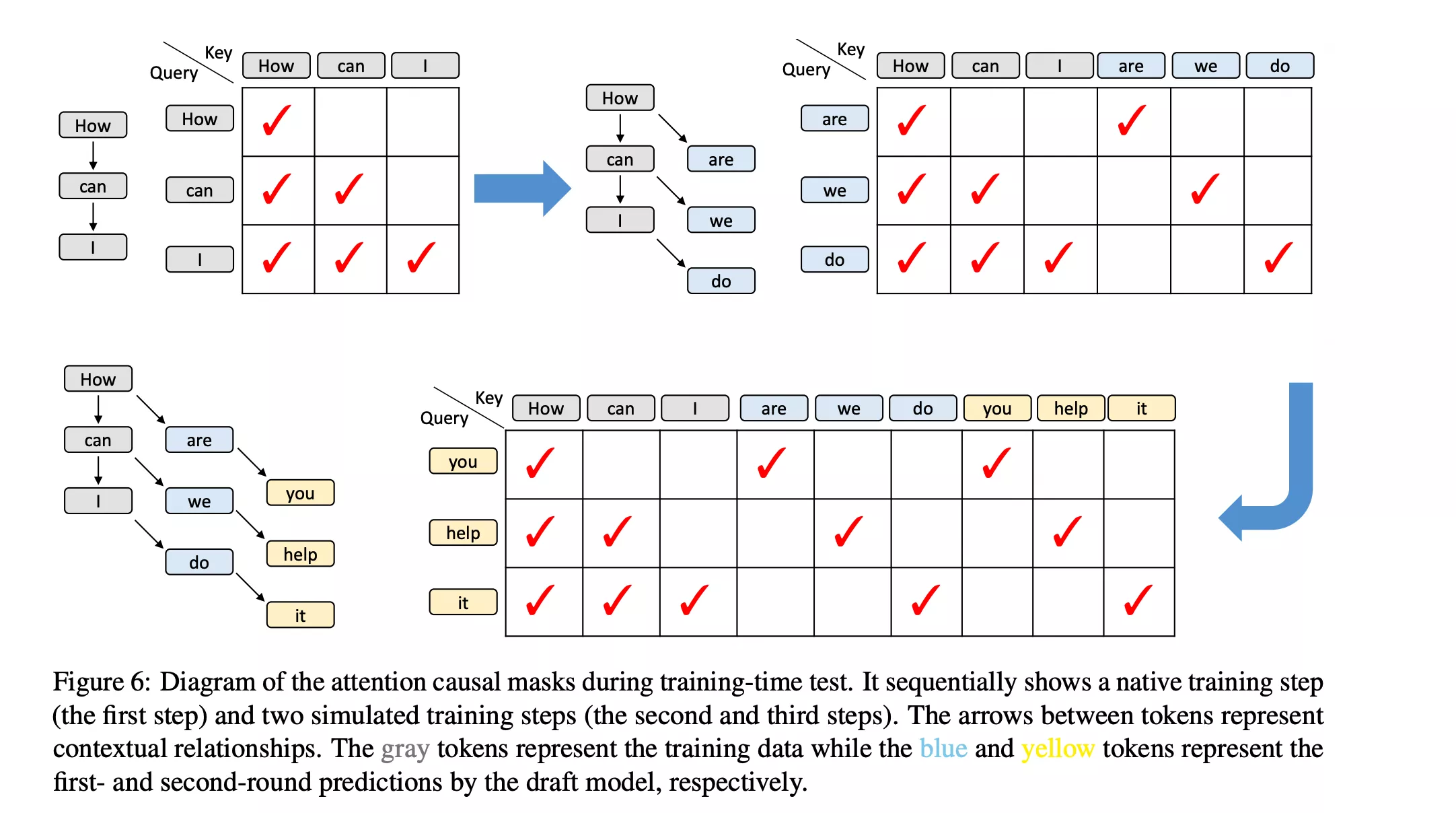
剪枝树对应的mask矩阵
在有了剪枝后的树后,在实际进行attention计算时会有mask操作,为了让前面的token看不到后面的值,下面这个图展示的就是对应剪枝树的mask矩阵:

EAGLE3
EAGLE3相比EAGLE1改变就是在结构,提高了精度
结构优化改动
在EAGLE1中,只取最后一个token的最后一层的LM Head之前的特征,在EAGLE3改成了会取最后一个token的前,中,后层的总共3个特征,然后做fc统一维度,取预测token的embedding和EAGLE1中是一致的,然后fc后的一个特征和embedding后的concat再做fc,这部分也是和EAGLE1是一样的
理解了流程图,区别就是原来采样最后一个,现在是采样前中后三个特征,然后多了一个fc把三合一,取的特征比原来的更多了,准确率上去了,就可以推理更多的token深度,TPOT就降低了
mask矩阵
这部分其实和EAGLE2也差不多,没啥多讲的
NGRAM算法
N-GRAM算法没有draft模板,是一种纯CPU的内存查表模板匹配方法
简单来说,它假设“历史会重演”。如果当前生成的片段在之前出现过,那么它后面跟着的内容大概率和之前一致。利用当前已经生成的文本历史,通过经典的 N-Gram 匹配来预测未来
流程
假设用户给了大模型一段代码或者一个长文本,现在模型正在生成一段重复性很高的回复。
历史文本 (KV Cache 中已有的内容):
"The user input is a Python script. This script is used to train a model."当前正在生成的片段:
"The user input is a"
第一步:匹配 (N-Gram Lookup)
算法会查看当前刚刚生成的最后几个 Token(假设
- 当前窗口 (Query):
["input", "is", "a"] - 检索历史: 算法在之前的文本中寻找哪里还出现过
["input", "is", "a"]。
很快,它在历史记录的前半部分找到了完全一致的片段:
"...The user [input is a] Python script..."
第二步:投机猜测 (Speculate)
既然找到了匹配,算法就“赌”后面的内容也一样。它直接从历史记录中把匹配片段后面的
Token 拿出来(假设猜测长度
- 预测的 Draft Tokens:
["Python", "script", "."]
第三步:验证 (Verify)
target model 一次性 接收
["The", "user", "input", "is", "a"] 加上预测的三个
Token。
verify和前面的EAGLE或者别的投机采样方法没啥区别
贪婪验证,拒绝采样
为了保证加入投机采样优化的无损,所谓“无损”,是指投机采样输出的序列分布(或贪婪结果),必须在数学上与仅使用Target Model直接生成的分布完全一致。
因此根据(Temperature = 0 或 Top-P/K 采样),分成了两种采样方式:
- 贪婪采样 适用于temperature为0
- 拒绝采样 适用于temperature不为0
贪婪采样
这个比较简单,它的目的是绝对确保:最终输出的每一个 token,都是target model在当前上下文下概率最大的那个 token。
所以只需要比较draft token和target model选出的概率最大的token是否一样,不一样就丢掉
拒绝采样
原理
拒绝采样的核心思想来自经典统计学,由 Yaniv Leviathan 等人在 2023 年提出
核心原理:保证验证后的输出分布与直接从 target model 采样完全相同。
公式
基本接受条件
对于 draft token
其中
等价形式
当
Bonus Token 采样
当某个 draft token 被拒绝后,需要从 调整后的分布 采样一个 bonus token:
其中
为什么这样做能保证分布正确?
数学证明:
设
情况 1:draft token
情况 2:从 bonus distribution 采样出
其中:
综合:
可以证明(经过代数化简):
这里的证明有点跳步骤了,可能不是特别清楚,可以把这整节给gemini让它讲更清楚点
结论:无论 draft model 的质量如何,最终输出分布都与 target model 完全一致。
SGLang 的实现
Python 层 (ngram_info.py:309-375):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
def _sampling_verify(self, batch, logits_output, sampling_info):
bs = batch.batch_size()
# 1. 计算 target_probs(应用 temperature, top_k, top_p)
target_probs = F.softmax(
logits_output.next_token_logits / expanded_temperature, dim=-1
)
target_probs = top_k_renorm_prob(target_probs, top_ks)
target_probs = top_p_renorm_prob(target_probs, top_ps)
# 2. 生成随机硬币(用于拒绝采样)
coins = torch.rand_like(candidates, dtype=torch.float32)
coins_for_final_sampling = torch.rand((bs,), dtype=torch.float32)
# 3. 调用 CUDA kernel
tree_speculative_sampling_target_only(
predicts=self.predict,
accept_index=self.accepted_indices,
accept_token_num=self.accept_length,
candidates=candidates,
uniform_samples=coins,
uniform_samples_for_final_sampling=coins_for_final_sampling,
target_probs=target_probs,
draft_probs=draft_probs, # N-gram 情况下为 0
threshold_single=...,
threshold_acc=...,
)CUDA Kernel (speculative_sampling.cuh:39-162):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
__global__ void TreeSpeculativeSamplingTargetOnly(...) {
DType prob_acc = 0.0;
DType coin = uniform_samples[bx * num_draft_tokens];
for (uint32_t j = 1; j < num_speculative_tokens; ++j) {
cur_index = retrive_next_token[...];
while (cur_index != -1) {
IdType2 draft_token_id = candidates[...];
DType target_prob_single = target_probs[cur_prob_offset + draft_token_id];
prob_acc += target_prob_single;
// 接受条件(SGLang 使用累积概率优化)
if (coin <= prob_acc / threshold_acc || target_prob_single >= threshold_single) {
// ✅ 接受 token
prob_acc = 0.;
predicts[last_accepted_retrive_idx] = draft_token_id;
++num_accepted_tokens;
break;
} else {
// ❌ 拒绝:记录 draft_probs 用于 bonus sampling
draft_probs[cur_prob_offset + draft_token_id] = target_probs[...];
cur_index = retrive_next_sibling[...];
}
}
if (cur_index == -1) break;
}
// Bonus token sampling:从 max(0, target_probs - draft_probs) 采样
coin = uniform_samples_for_final_sampling[bx];
DType sum_relu_q_minus_p(0);
for (uint32_t i = 0; i < ceil_div(d, BLOCK_THREADS * VEC_SIZE); ++i) {
// 加载 target_probs 和 draft_probs
q_vec.load(target_probs + ...);
p_vec.load(draft_probs + ...);
// 计算 ReLU(q - p)
for (uint32_t j = 0; j < VEC_SIZE; ++j) {
relu_q_minus_p[j] = max(q_vec[j] - p_vec[j], DType(0));
}
sum_relu_q_minus_p += BlockReduce(...).Sum<VEC_SIZE>(relu_q_minus_p);
}
// 从调整后的分布采样
DType u = coin * sum_relu_q_minus_p;
DeviceSamplingFromProb(..., u, relu_q_minus_p_vec, ...);
predicts[last_accepted_retrive_idx] = temp_storage.sampled_id;
}SGLang 的优化阈值
SGLang 引入了两个阈值参数来提高接受率:
1
2
3
# 参数
threshold_single = get_global_server_args().speculative_accept_threshold_single
threshold_acc = get_global_server_args().speculative_accept_threshold_acc接受条件:
1
2
3
if (coin <= prob_acc / threshold_acc || target_prob_single >= threshold_single) {
// 接受
}threshold_single:单个 token 概率阈值,如果 target_prob ≥ threshold_single,直接接受threshold_acc:累积概率阈值,降低接受门槛
权衡: 这些阈值会轻微改变输出分布,但可以显著提高接受率。
N-gram 的特殊情况
对于 N-gram,没有 draft model,因此
draft_probs = 0。
拒绝采样变为:
SGLang 的实现中,当 draft_probs = 0 时:
- 接受条件简化为检查
target_prob是否满足阈值 - Bonus sampling 退化为直接从
target_probs采样
1
2
3
4
if (num_accepted_tokens != num_speculative_tokens - 1) {
// 有 draft_probs 时才加载
p_vec.load(draft_probs + ...);
}一些别的想说的
- MTP结构是模型原生layer,也会更难训练,一般要基座模型厂家才能训,需要大量数据集,而EAGLE可以选择更简单易收敛的模型结构,数据集要求没那么高,适合后训练
- 我司线上用的也是EAGLE3,用的llama结构MQA+稠密FFN,多专家moe一般很难训,很难收敛;因为我们推理用的sglang,训练eagle3就使用了同社区开发的SpecForge









