量化-04-SmoothQuant

量化-04-SmoothQuant
gogongxtSmoothQuant
之前我们讲的算法是OBQ/GPTQ是量化权重的,把权重量化到W4/8,实际计算时还要转成bf16,并没有使用上INT8 tensor core加速计算
为了实现这个,我们就需要去量化激活值,这篇要介绍的SmoothQuant也是近几年来简单并且适用范围非常广的方法
对于LLM的激活值观察:
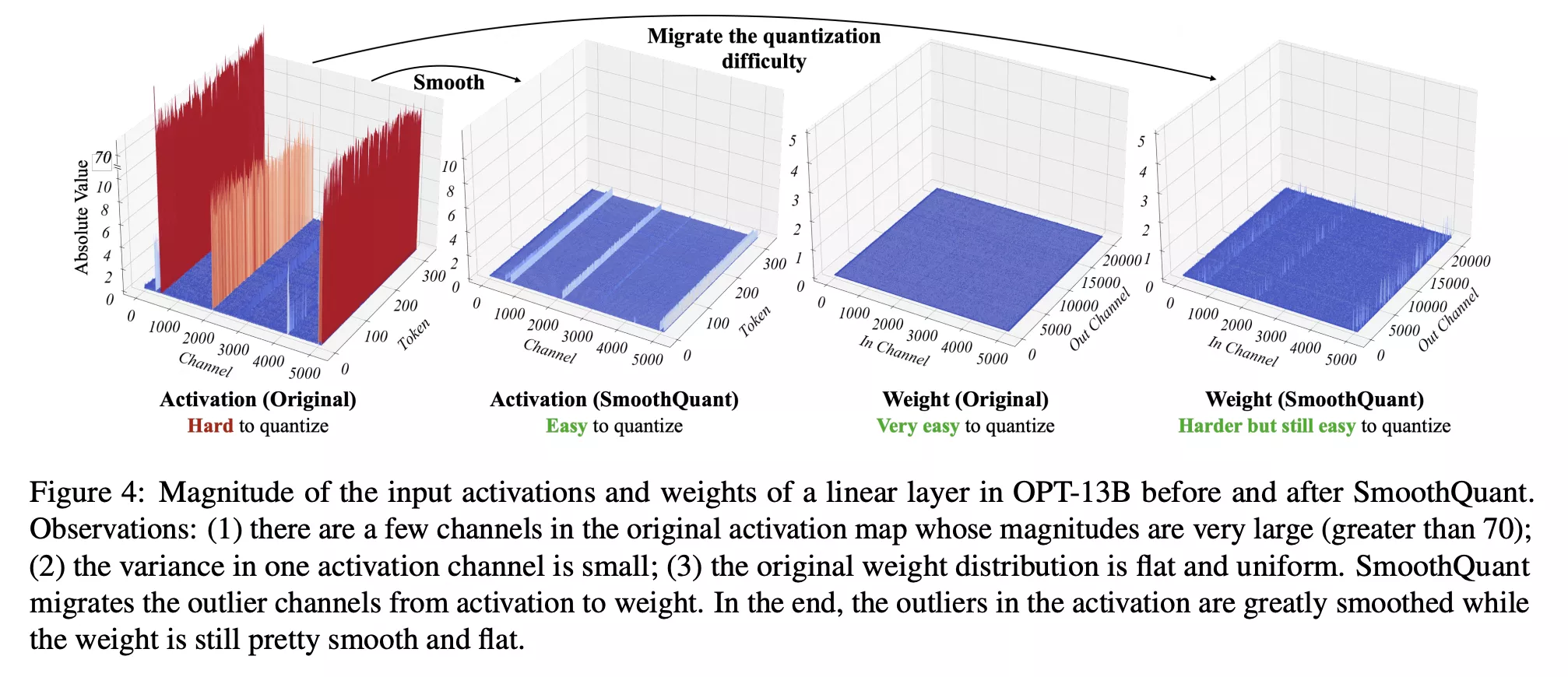
在LLM中,少数通道的 outlier 主导了量化范围,并且这部分都是分布在特定的通道上,普通值有一定比例关系,我们可以考虑把这部分异常比例关系移到权重上,让激活值变得平滑,Max更小更好量化
核心思想:等价缩放,迁移难度
回到线性层的基本运算
注意矩阵”左行右列”,就好理解了,数学上完全等价,输出
物理直觉:假设第
- 激活第
通道被缩小 10 倍,max 从 100 降到 10,量化精度大幅提升 - 权重第
通道被放大 10 倍,max 从 0.5 变成 5,权重本身范围小,放大后仍在 INT8 舒适区内
这就是 SmoothQuant 的全部思想:权重有富余的量化容量,激活没有。等价缩放让两者各归其位。
量化方式
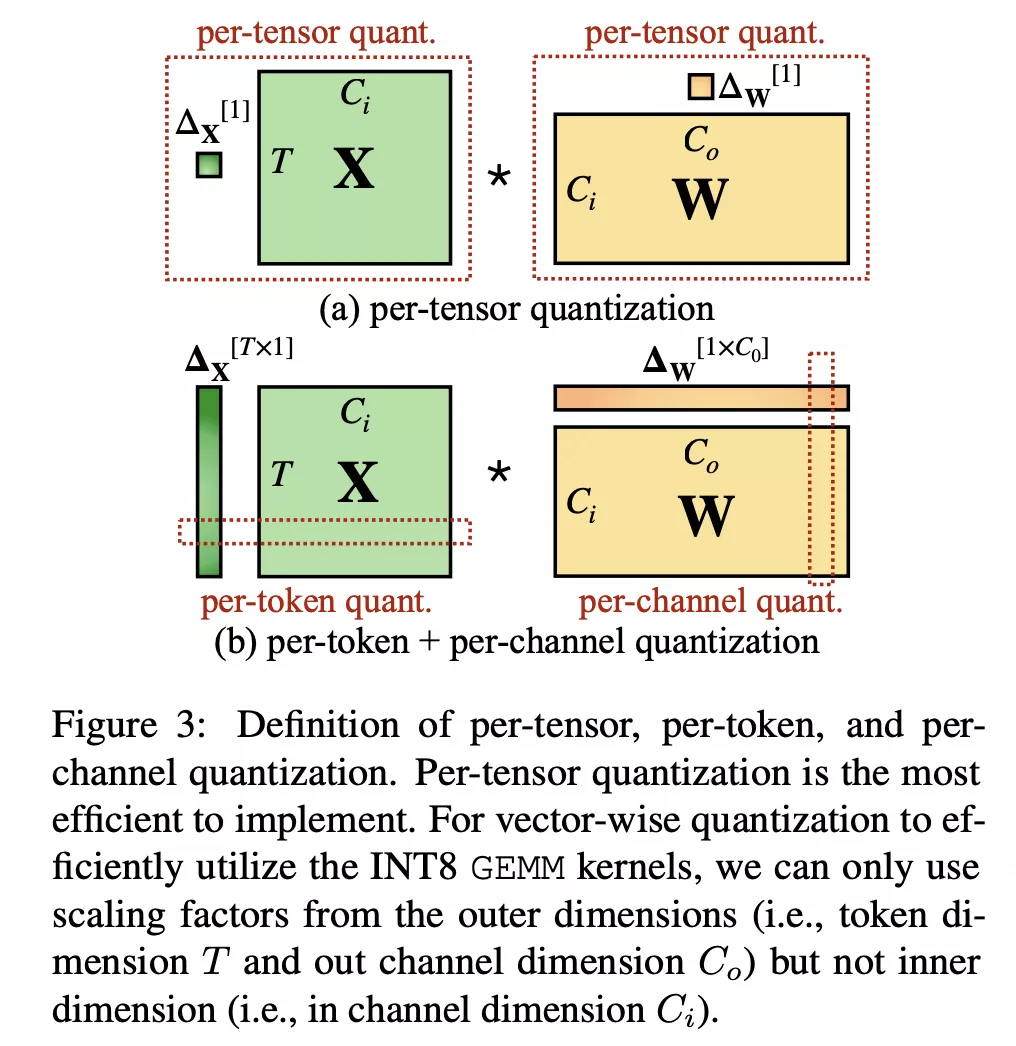
注意下这里的矩阵维度定义是
因为这部分outlier是跨token的,也就是集中在X矩阵的列上,因此非常适合:
- 激活值用per-token
- 权重用per-channel
Smoothing Factor 怎么算
核心问题:
SmoothQuant 给出的公式是:
逐项拆解:
:激活第 个通道的绝对值最大值,衡量该通道 outlier 的严重程度 :权重第 个通道的绝对值最大值,衡量该通道能承纳多大的放大 :迁移强度,控制把多少量化难度从激活搬给权重
当
为什么是几何平均? 因为缩放是乘法操作。激活缩小
为什么用 max 而不是 mean/std? Outlier 本身就是极值问题。max 直接捕捉最坏情况,mean 会被大量正常值稀释,对 outlier 的感知能力太弱。
α 的选择
:不平滑, ,激活该炸还是炸 :全部迁给权重, ,激活完全归一化但权重可能撑不住
规律直觉:模型越大,激活 outlier 越严重,需要更大的
工程实现
SmoothQuant执行的实际上是权重量化的前处理操作,然后把系数乘到对应的权重矩阵中
我们不想在推理的时候真的去把激活值乘上系数,所以考虑:
- 激活值的系数乘到上一个算子的权重
- 权重的系数就乘到自身权重
下面我们以典型的 RmsNorm -> Gate (Linear)
结构为例,通过数学公式来推导这种融合的等价性。
标准 RMSNorm 的公式
对于输入
其中:
- 均方根值
,这是一个标量(对于每个 token 而言)。 是模型训练学到的缩放权重(Scale Weight)。 表示逐元素乘法(Element-wise multiplication)。
SmoothQuant 等价融合推导
根据 SmoothQuant
的逻辑,我们需要将当前层的输出激活值平滑化,即乘上对角矩阵
将 RMSNorm 的公式代入上面的平滑化公式中:
因为
由此可以非常直观地看出,我们只需要定义一个新的 RMSNorm 权重:
由此outlier的处理我们已经在权重中处理完了,SmoothQuant 部署推理时没有任何额外计算开销。
校准流程
- 用 128 条校准样本过模型,收集每层输入激活的
- 读取每层权重的
- 计算
,对权重做缩放融合 - 对融合后的权重做 W8A8 量化(RTN 就行)
- 保存量化后的模型
整个过程只需要一次前向传播收集激活统计量,不需要像 GPTQ 那样逐列迭代,也不需要计算 Hessian 矩阵。
总结
SmoothQuant 的一句话核心:等价缩放变换,把激活的量化难度迁移给权重。
工程实现极简、推理零开销、效果稳定(大部分模型 α=0.5 即可),是 W8A8 场景下的首选方案。
- α 需要手动调。 虽然大部分模型 0.5 就行,但碰到极端分布的模型还得试。这不是一个完全自动化的方案。
- 本质上只是一个”预处理”手段,量化本身用的还是最朴素的 RTN。
- 只处理了通道间的幅度差异,没处理分布形状。 Scaling 只能调范围,不能改变激活的分布形状。如果你的激活在某些通道上有严重的非对称分布(大量正值 + 少量极大负值),还需要 Shifting(平移)来处理。例如 Outlier Suppression+ 和 OmniQuant 的 Shifting + Scaling 组合。
对于上面碰到的问题,华为的msmodelslim做了一下改进,提出了Flex Smooth Quant 主要增加更智能的
计算和增加了激活值的Shifting









