通信操作

通信操作
gogongxt通信操作
主要介绍AllGather和AllReduce,别的通信操作可以参考下面的文档
AllGather
示意图:
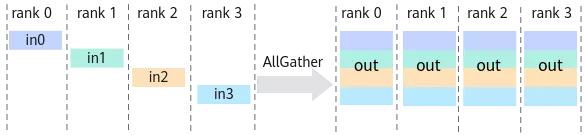
每张卡上都有一个矩阵的一部分,AllGather让每张卡都有完整的矩阵
ring-AllGather 算法:
所谓ring,就是环形处理,每张卡把输出传到下一张卡:
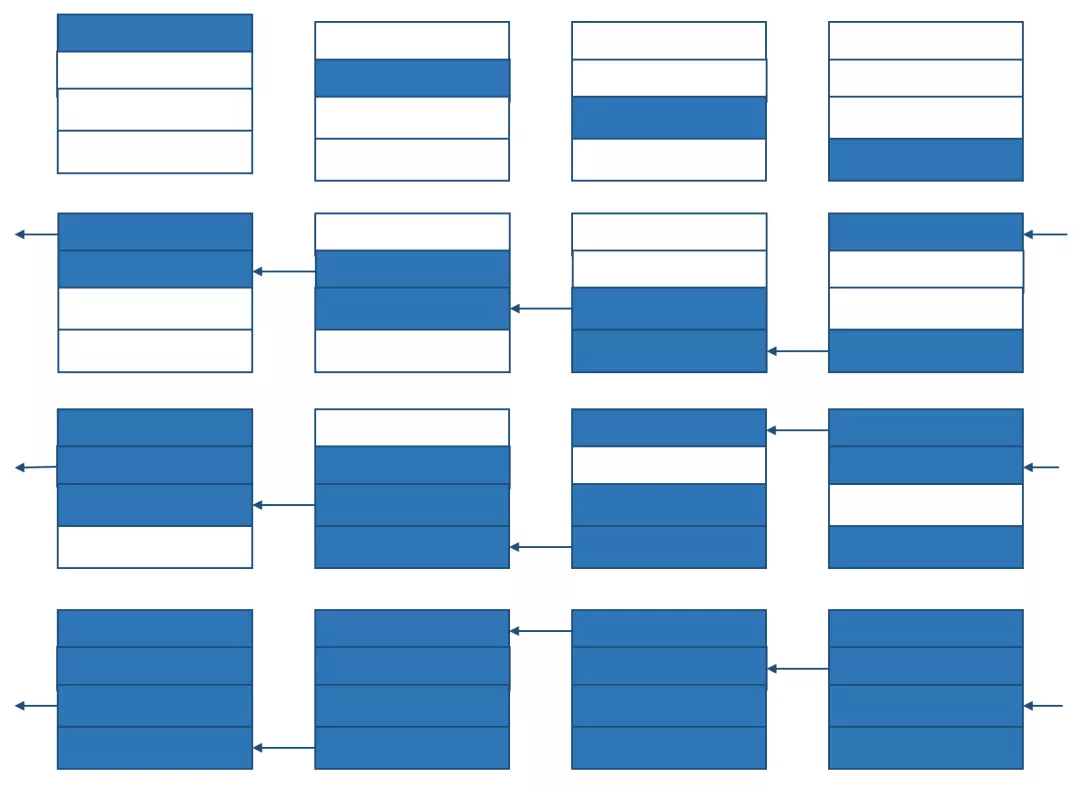
假设一个
注意我们讲的通信量一般都是单向的,计算效率是也是除上单向的带宽
AllReduce
示意图:
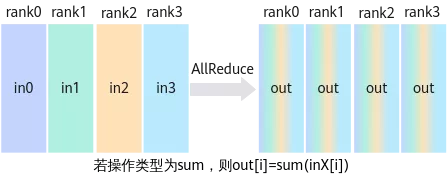
AllReduce操作是将通信域内所有节点的输入数据进行归约操作后(支持sum、prod、max、min),再把结果发送到所有节点的输出buffer。
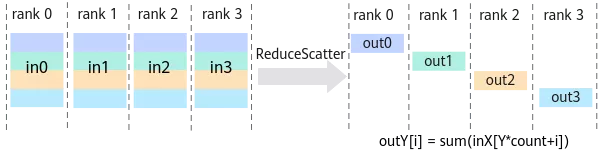
分成两步:ReduceScatter + AllGather
ReduceScatter示意图:
ring-AllReduce完整流程示意图:
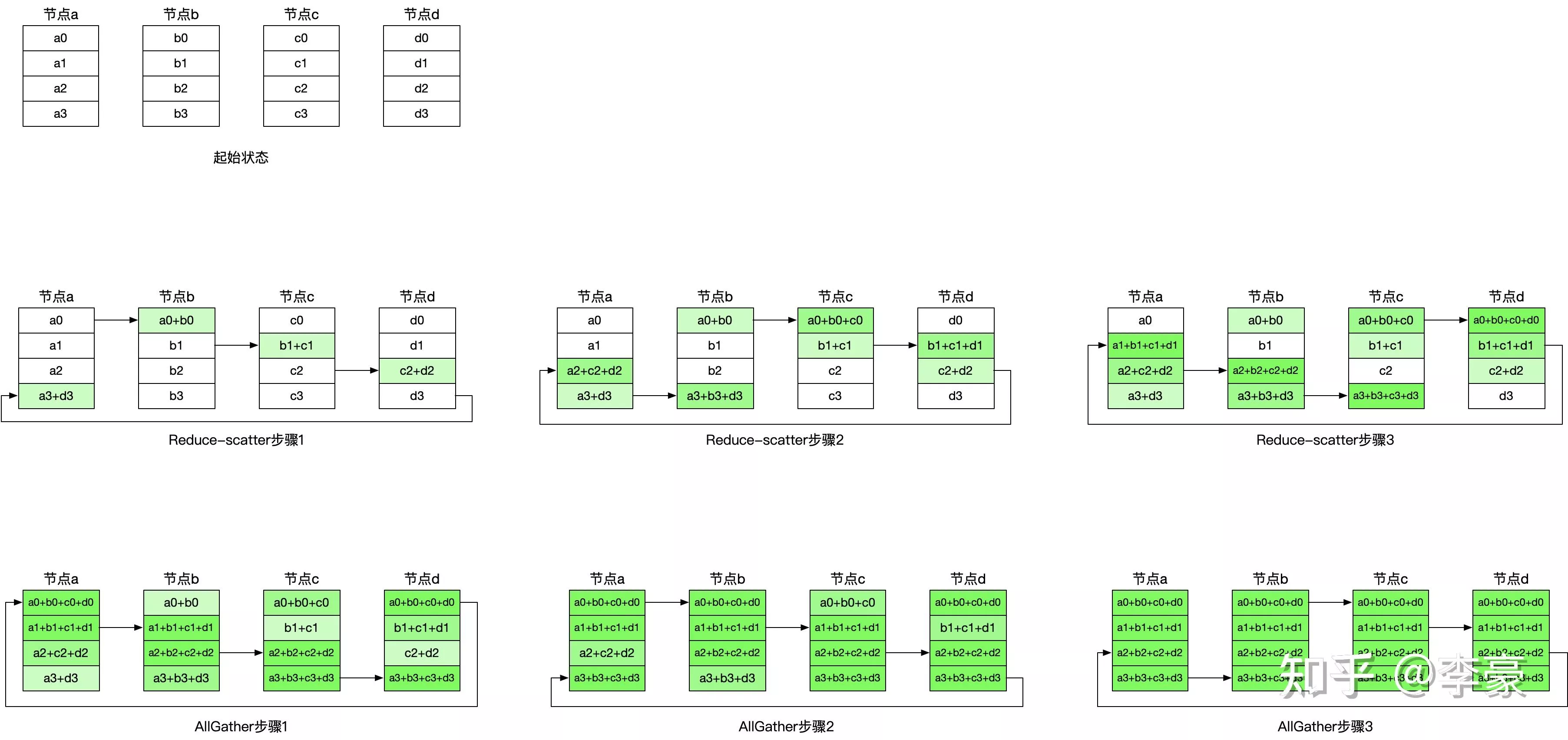
ReduceScatter的通信量和Gather一样,也是
大模型推理中的应用
矩阵切分方式
考虑TP切分,分成两个两种切分方式,行切分和列切分
对于矩阵乘法
列切分
矩阵
被切片为 块,每卡持有的形状为 。输入矩阵 (形状 )需要在所有节点上拥有完整的副本 - 计算量: 每张卡的计算量为总计算量的
,即 FLOPs - 通信量: 如果后续算子需要完整尺寸的结果矩阵
,则需要执行一次 AllGather操作来拼接各卡的, 在典型的 Ring AllGather算法中,单卡的通信量约为
- 计算量: 每张卡的计算量为总计算量的
行切分
矩阵
被切分为 块,形状为 。输入矩阵 同样切片,各卡只持有 的分块 - 计算量: 每张卡的计算量同样是
FLOPs - 通信量: 各卡算出的结果
形状已经是完整的 ,但这只是一个部分和。还需要执行一次 AllReduce操作, 通信量为
- 计算量: 每张卡的计算量同样是
所以两种切分方式的计算量完全相同,通信量行切分为列切分的两倍
实践上存在列-行组合抵消通信:
在前馈网络(MLP)或注意力机制(Attention)中,将第一个线性层设为列切分。它的输出形状恰好是被
推理中的应用
我们先关注TP中会用到的通信操作,以常规MHA/GQA架构来说,在以下位置计算完成后存在通信:
| # | 位置 | 类型 |
|---|---|---|
| 1 | VocabParallelEmbedding | all_reduce (SUM) |
| 2 | LinearOProj (Attention O投影) | all_reduce (SUM) |
| 3 | LinearRowParallel (dense/moe MLP down) | all_reduce (SUM) |
| 4 | ParallelLMHead | all_gather |
矩阵切分方式:
- VocabParallelEmbedding 按照行切分
- qkv 按照头个数切分(本质列切分)
- o_proj 行切分,可以和qkv计算配合起来,减少一次通信
- gate/up proj 列切分
- down proj 行切分,和gate up的列切分配合起来
- LMHead 无需配合按照列切分,减少通信量
注意几点:
- qkv是按照头个数切分的,每张卡算完全不同的头,由于计算完后理应在dim=-1拼接起来(实际不会),所以可以理解为这里是列切分
- 对moe模型来说,gate门控算出专家和专家概率和是LinearReplicated,权重完全复制的
- silu激活和mul,都只和当前元素有关,所以不需要通信
- 为什么VocabParallelEmbedding用行切分?因为LMHead用列切分可以比行切分减少一倍通信量,而某些模型Embedding和LMHead是共享权重的(tie word),两个矩阵乘刚好又是转置的,所以在共享权重下Embedding自然就是行切分了。虽然实际上如果不是共享权重,完全也可以用列切分来减少通信量,但是维护一份代码来说,当前的实现也比较方便
- LMHead后,进行all_gather得到完整的logits,然后每张卡都会进行采样sample得到token,更新token_pool,tp0的用来返回给api









