
NOTE
前两节我们讲了进程的关系和每个进程的作用,和用户发送请求后的http流转流程
这一节我们接着从请求的视角,来讲router调度请求和实际执行推理
Router 是 nano-sglang 框架中的核心调度组件,负责接收来自 Tokenizer
的请求队列,管理内存池,调度 Prefill 和 Decode 操作,并将生成的 token
发送给 Detokenizer。
核心调度流程
请求接收与转换
Router 通过 exposed_step 方法接收来自 Tokenizer
的请求:
123456789def exposed_step(self, recv_reqs):
"""被异步包装的函数,recv_reqs就是zmq接收到的队列,异步执行当前的step调用推理"""
# 把请求从TokenizedGenerateReqInput格式转换成推理中的Req类型,并做一些初始化操作
for recv_req ...

563208b6680b75fe5d406519e5616e6fc6f08cfa77c43130f3ddf93ad6c4aabc4d850efad4dc9a554f3168f448489a05251c4876a3621ac44d39009c8df55cc6553811672bb17d453d794562742020fb25d49ab51f33cdb8662e81f9fa48298dcfc8fda74129894c736bd0f128a83f3d2ad84a8fd500f0cfe160160f4bcc7c37fb77ee2bf565b432a5dddf616be51cf34592f816fb90443d89c2f1010628f66594d1abc791b7d77731e420ef10695e6ec29e4e6042d43f2771493622b8b53c4fb8fe80f8057914eca7722ad7a05765168a9d159be1b61cb239d3013a5b6262fc03179300b1348c11b547d57fcf32fb64f4439bceec646fdc1 ...
无论是基于提示词还是基于api的function
call,本质上都是token的处理
基于提示词的function call
是把结构化的输出要求放到system prompts中,再对回复做function
call的正则匹配
基于api的function call
则是交给推理框架处理,请求时带上对应的tools字段,推理框架会把tools的内容做tokenizer和prompts放到一起,总之输入肯定也就是tokens,对输出则是推理框架去通过正则匹配function
call的结构化输出,匹配上了就认为是function
call的调用,返回响应finish_reason对应为function_call,如果没匹配上,就认为是普通文本输出
NOTE
下面将以sglang+qwen+非流式讲一讲sglang是怎么处理parse
function call的请求和返回的
首先是sglang启动qwen模型有加上
--tool-ca ...
png)
NOTE
本文参考自 https://oigi8odzc5w.feishu.cn/wiki/LWqEwXNkBibT0ykrbI0cvptBnAf
基于API的Function Call大模型调用示例代码
代码示例:
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788899091929394959697989910010110210310410510610710810911011111211311411511611711811912012112212312412512612712812913013113213313413513613713813914014 ...
使用docker部署easyimage图床
使用docker-compose部署
1234567891011121314151617version: '3.3'
services:
easyimage:
image: docker.1ms.run/ddsderek/easyimage:latest
container_name: easyimage
ports:
- '61021:80'
environment:
- TZ=Asia/Shanghai
- PUID=1000
- PGID=1000
- DEBUG=false
volumes:
- './data/config:/app/web/config'
- './data/i:/app/web/i'
restart: unless-stopped
typora通过picgo-core使用easyimage图床
配置picgo-core
安装和配置picgo-core:
12npm ...
TokenizerManager
流式响应架构详解
总体概览:
sequenceDiagram
participant User as 用户
participant API as FastAPI Server
participant TM as TokenizerManager
participant Router as Router进程
participant Model as Model RPC
participant Detok as Detokenizer
User->>API: POST /generate (GenerateReqInput)
API->>API: obj.post_init()
API->>TM: generate_request(obj)
TM->>TM: 第一次请求创建handle_loop
TM->>TM: tokenizer.encode(text)
TM->>TM: ...
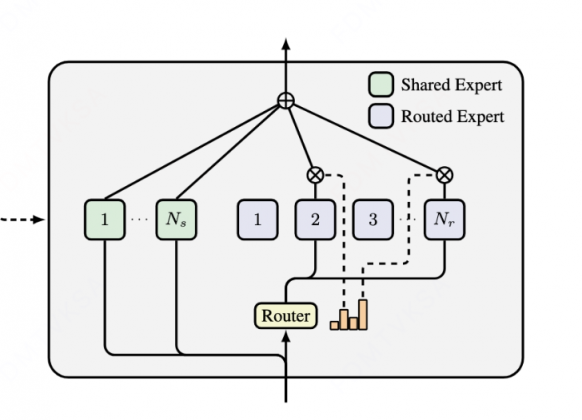
mlp计算流程
先来看一下上图经典mlp的计算:
gate和up的proj,可以cat起来一起算
gate后有一个silu激活,激活后的值和up后的进行点乘,这两个操作也是一起做的
点乘结果给到down_proj就是最后的输出
对于非moe的mlp计算,qwen2和qwen3都一样的用的类Qwen2MLP
核心计算MergedColumnParallelLinear和RowParallelLinear就是使用torch.linear的计算,如果是tp,就是直接进行矩阵分块
12345678910111213141516171819202122232425262728293031323334353637383940414243class Qwen2MLP(nn.Module):
def __init__(
self,
hidden_size: int,
intermediate_size: int,
hidden_act: str,
quant_config: Optional[Qu ...
SGLang源码解析封面
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133134135136137138139140141142143144145146147148149150151152153154155156157158159160161162163164165166167168169170171172173174175176177178179180181182183184185186187188189190191192193194195196 ...
143a5a50a47c0b7d448749907319f4bcc0d8dad15a6dabde8c53c22ae26fc3e82f7aa239b9d442eadeedcf2bb516f7f30e0c9f26619f0c86b5ab908be5cf35b133b72455a9fdac29e0f9010e2a5ba1fd2f431cd9cc06fef021ffb6b3f5a4279e2d13385da883494434e34c068d5041bf605701fbaf2c1c45c590c59a1ff7a3af64bdd36d51eb5eed32f25ac88e50bc1d2fb3c87d0beb44bf51bb2955873c4ef978026cf2992e27c1071aa911998544c30e01334d361ddac802d3deb84738d03cb794f5e49080c102b60504f1995c3be102b0f08c6687507e42d4211bbeb3f630f052aaccc1997fc74ea7b39a67db9de26db60478757833f02 ...
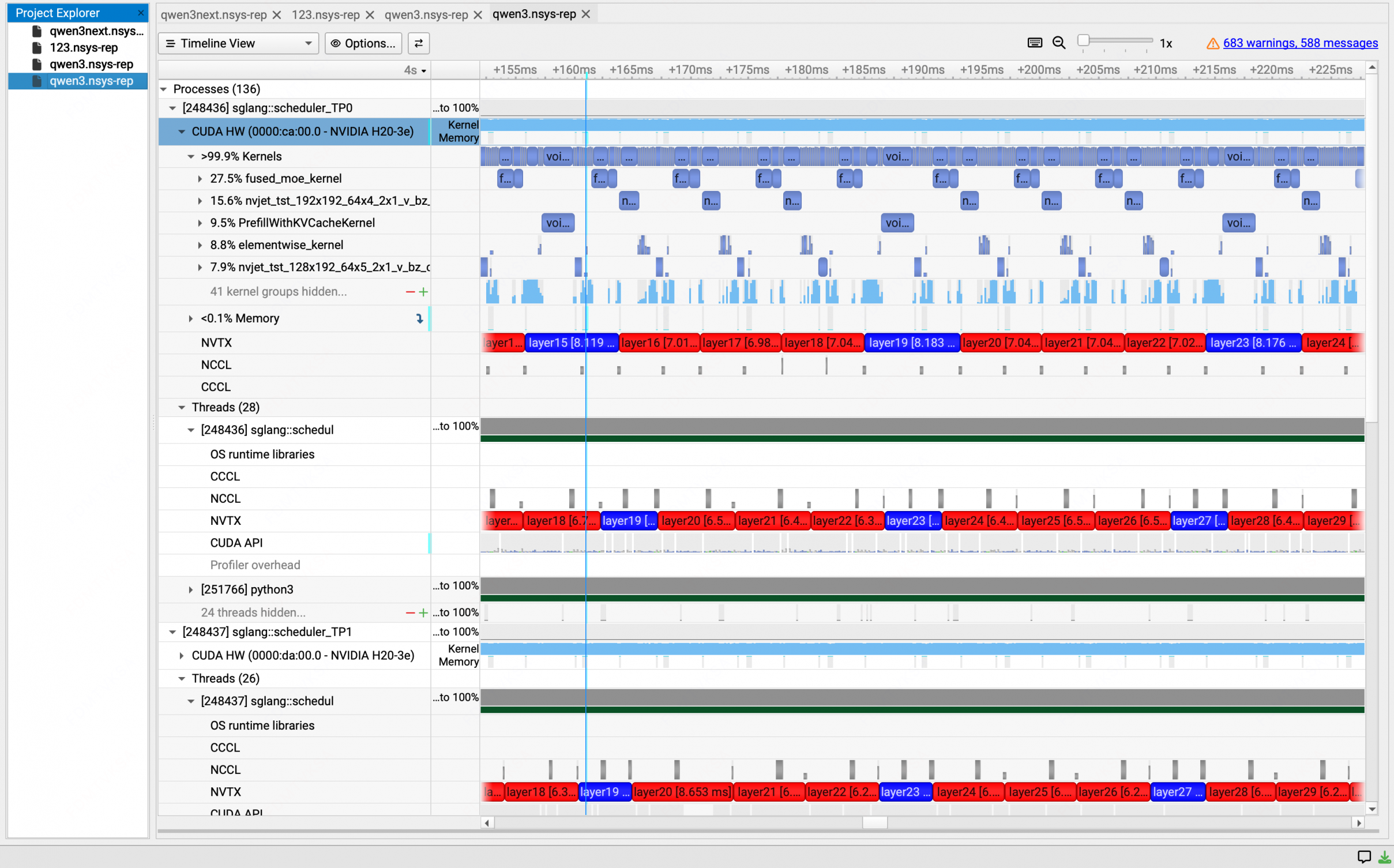
进程结构
tp=1的情况 总共三个进程
启动命令:python3 -m sglang.launch_server --model-path /tmp-data/models/llama-2-7b --port 30000 --mem-fraction-static 0.8 --tp 1
查看进程树:ps -aux —-forest
123luban 3049112 21.6 0.0 7700748 758940 pts/6 Sl+ 11:48 0:09 | \_ python3 -m sglang.launch_server --model-path /tmp-data/models/llama-2-7b --port 30000 --mem-fraction-static 0.8 --tp 1
luban 3052085 32.5 0.0 56482984 769368 pts/6 Sl+ 11:48 0:06 | \_ python3 -m sglang.launch_server --model-path /tm ...






